搜索引擎原创识别与站内权重继承算法解析
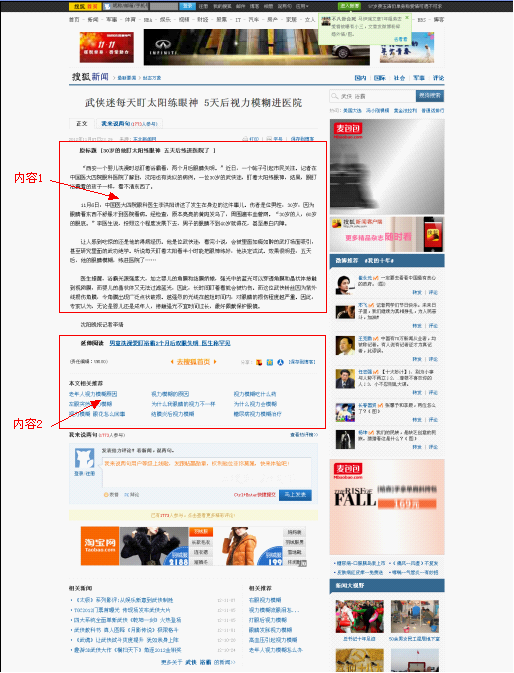
2.内容2一般紧邻着内容1。而且内容2中的链接锚文本,与内容1存在相关性。
首先要明确一点,本文探讨范围仅限内容页,而非专题页、列表页和首页。
备注1开始:
由此可见,我需要重视两类文章即可。一是原创文章,二是有价值的信息聚合站点下的文章。
但很少有人会说为什么,而越来越多的人因为不明其内在道理,而渐渐忽视了这些细节。当然,以前的一些搜索引擎算法在内容上的注重程度不够,也起到了推波助澜的作用。但是,如果从阴谋论的角度上来看,我可以假设出这么一个道理。
绝大部分用户的搜索页面,第一页只有10个结果,除去我自家产品,往往仅剩下7个左右,一般用户最多只会点击到第3页,那么我需要的优质站点其实不到30个就可以最大限度的满足用户体验。那么经过3-5年的布局,逐渐筛选出一些耐得住寂寞和认真做细节的站,这时候我再将这一部分算法进行调整,进而筛选出这些优质站点,推送给用户。当然,在做的过程中还有更多的参考因素,比如域名年龄、JS数量,网站速度等。
上图中很明显内容1是用户最为需要的,内容2是用户可能感兴趣的,其余均是无效的噪音。那么针对于此,我们可以发现如下几特征:
在此之前,我们先明确我们的目的。
由此,对于原创文章的判断就结束了。好了,苦逼烦闷的枯燥讲解告一段落,下面我用大白话再重新复述一遍。
其次,很多SEO他们懒,进行所谓的伪原创,你说你伪原创时插入点自己的观点与资料也成,结果你们就是改个近义词什么的,于是我就用到了特征向量,通过特征向量的判断,把你们这些低劣的伪原创抓出来。关于这个,判断思想很简单,你权重最高的前N个关键词集合极为相似的时候,判断为重复。这里所谓的相似包括但不仅仅局限于权重最高的前N个关键词重合,于是构建了特征向量,当对比的两个向量夹角与长度,当夹角与长度的差异度小于某个特定值的时候,我将其定义为相似文章。
如果是我,我会喜欢什么样子的文章呢?我会喜欢我的用户喜欢的文章,如果硬要加判定标准,那无外乎是两种:1.原创且用户喜欢。2.非原创且用户喜欢。在这里,我的态度很明显,伪原创就是非原创。那么用户喜欢什么样的文章呢?很显然,一些新观点、新知识往往是用户喜欢的,也就是说通常原创文章都是用户喜欢的,而且即便用户不喜欢,原创站点作为新鲜内容的制造者,也应该受到一定的保护。那么非原创的文章用户就一定不喜欢吗?诚然否也。一些站点,其内容往往是经过搜集整理后聚合而成的,那么这些站点对用户来说就是有价值的,其相对应的文章理应获得较好的排名。
2.内容中如何提取出关键词?
有很多人问过我,说Mr.Zhao啊,百度如何判断伪原创和原创?百度喜欢什么样的文章?什么样的文章比较例如获得长尾词排名?等等诸如此类的问题。面对这些问题,我常常不知如何回答。如果我给一个比较大方向一些的答案,例如要重视用户体验、要有意义等等,那么提问者会觉得我在应付他,他们往往抱怨说这些太模糊。可是我也没法再给出具体的内容,毕竟我不是百度,具体算法我又何德何能的为你们指点江山呢?
拓展阅读1开始:
首先,你的内容一模一样,一个字都不带改的,那肯定是摘抄的啊,这时候MD5散列值就能迅速的判断出来。
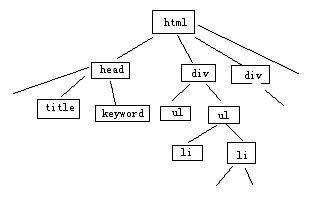
从网页的标签布局上来看,网页是通过若干的信息块来提供内容的,而这些信息块又是由特定的标签规划出来的,常见的标签有div ul li p table tr td 等,我们依照这些标签,将网页费解为树状结构。
内容除噪,并非大家经常性的误以为仅仅除去代码而已。对于我来说,我还要出去页面部分非正文内容的文字。比如导航条、比如底部文字以及各个文章列表。将它们的影响除去后,我将得到一段仅仅包含网页正文内容的文本段落。写过采集规则站长朋友应该知道,这个并不难。但搜索引擎毕竟是一款程序,不可能针对每个站写个类似于的采集规则的东西,所以我需要建立一套除噪算法。
上图是我手绘的简单的标签树,通过这种方式,我可以非常轻松的识别出各个信息块。然后我设定一定阙值A为内容比重阙值。内容比重阙值为信息块中文本字数与标签出现此处的比值。我设定当网页中信息块内容比重阙值大于A时,才会被我列为有效内容块(此举是为了杜绝过分的多内链,因为如果一篇文章布满内链,则不利于用户体验),然后我再比对内容块中的文本,当其具有唯一性时,此一个或多个内容块的集合,即为我所需要的“内容1”。
那么针对聚合站点,我可以通过“内容2”来进行粗略的判断。简而言之,如果是一个良好的聚合站点,首先其内容页必须存在内容2,同时内容2必须占重要部分。
那么,针对于此,我采用广为人知的标签树方式,将内容页进行分解。
那么我在甄别这两类文章之前,我需要先进行信息的采集。本文对于spider程序部分不进行阐述。当spider程序下载下来网页信息后,在内容处理的模块中,我需要先对内容除噪。
则我计算出两个公式。
1.所有的调用列表全部是在一个信息块里,这个信息块绝大部分是由标签组成,即便有游离于标签的内容,其文字也基本是固定的,且在站内页面中存在大量重复,较为容易判断。
3.内容中关键词的权重值是如何赋予的?
现在基本上搜索引擎对于原创的识别,在大面上采用的是关键词匹配结合向量空间模型来进行判断。Google就是这么做的,在其官方博客有相应的文章介绍。这里,我就做个大白话版本的介绍,争取做到简单易懂。
3.内容1部分,是有文字文本内容和标签混合而成,且在通常情况下,文本文字内容在网站网页集合中具有唯一性。
拓展阅读2开始:
那么内容2我要如何处理呢?在讲解处理内容2之前,我先讲解一下内容2的意义。正如我先前所说,如果是一个注重用户体验的聚合性网站,那么他的作用是将现有的互联网内容经过精心的分类与关联,来方便用户更好、更有效的阅读。针对这样的站点,即便其文章不是原创而是从互联网上摘抄的,我也会给予其足够的重视与排名,因为它良好的聚合内容往往更能满足用户的需求。
一直关注google反作弊小组官方博客的朋友们,应该看过google关于相似文章判断算法的那篇博文,在那篇文章中,其主要使用的是余弦定理,就是主要计算夹角。不过后来Mr.Zhao又看了好几篇文献,觉得那篇博文应该仅仅是被google抛弃后才解密的,现在大体算法的趋势,应该是计算夹角与长度,所以选择现在给大家看的这个算法。
