探讨SEO技术问题,如何使用机器学习预测谷歌搜索排名?
在 2015 年年末的时候,我们开始越来越多地听说机器学习以及它在处理大量数据上的能力。我们越认真工作,它就变得越专业,而且很快它就会帮助我们运转这个世界。
我们试过两种 TF-IDF 方式,只得到依赖于模型的略微不同的结果。第一种方式由首先连接所有的文本特征构成,然后应用 TF-IDF 算法(也就是说,单个实例的所有文本列连接而成文件,一系列这样的实例构成语料库)。第二种方式是指对每个特征分开应用 TF-IDF 算法(也就是说,每个单独的文本列是一个语料库),然后连接由此得出的数组。
为了预处理文本特征,我们使用了 TF-IDF 算法(检索词频率,反转文档频率)。此算法将每个实例视为文件,并将所有实例集合视为一个语料库。然后,它为每个词赋予分数,词汇在文件中出现的频率越高,在语料库中出现的频率越低,那么其分数就越高。
我们决定试试能否使用抓取工具、排名追踪、链接工具和其他一些工具的可用数据来预测网页排名。我们知道完全预测正确的可能性非常低,但我们仍能在利用机器学习上获得一个了不起的成功。
我们使用了一个有 20 万条记录的数据,包括大约 2000 个不同的关键词/搜索词。总体上,我们可以把这些关键词依据属性分为以下几类:
文本生成、总结和归类。
特征工程
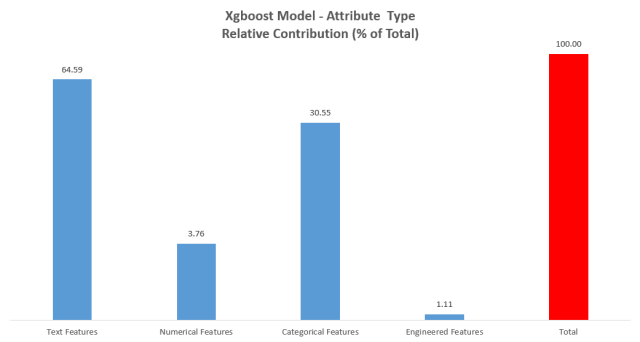
下面的图表揭示了特征类别对此模型最终预测的准确率做出的相对贡献。与神经网络不同, 伴有其它模型的 XGBoost 允许你轻易地窥视模型内部,从而判断特定特征持有的相对预测权重。
结论
永远不要写另一个 ALT 参数
在 2015 年末,JR Oakes 和他的同事利用机器学习做了一个实验,试图预测某个特定网页的谷歌搜索排名。下面这篇文章是他们的发现,他们希望这些成果能够帮助到 SEO 从业者。
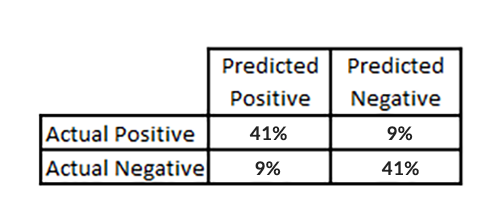
为了衡量这个算法的性能,我们决定使用混合矩阵。
就像我之前说的,我不会讲很多关于机器学习的细节,但重要的是掌握下面这几点。总的来说,现在的大部分机器学习工作都是在处理回归、分类和聚类算法。我将在这里定义前面两个,因为它们与我们的这个项目有关。
观察用户行为和对访客归类/打分的新方法
最后一步是连接所有从特征类别中得出的行列形成一个数组。这是我们做完以上所有步骤(理清特征,将分类特征转变为标签并在标签上运行独热码,应用 TF-IDF 算法于文本特征并将所有特征按比例排列到平均值两端)后再去做的。
通过语音和智能Q&A问答的文本、产品、推荐系统来进行导航的新方法。
我们认为对于测量模型有效性的最有代表性的度量是混淆矩阵。混淆矩阵是一种可视化的表格,主要用于比较分类结果和实际测得值。混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。
结果
类别变量是指一个可以表示有限数量的值,每个值代表一个不同的群体或类别。
XGBoost 是「极端渐进增长(Extreme Gradient Boosting)」的简称,渐进增长是「一种针对回归和分类问题的机器学习技术,它生成弱预测模型集成形式的预测模型,典型的是决策树。」
机器学习正在越来越快地成为很多大公司的一个不可获取的工具。相信每个人都听说过谷歌的人工智能算法打败了前世界围棋冠军,以及谷歌的搜索结果排名算法 RankBrain。机器学习早就不是数学研究者们的神秘课题了。在有大量数据的行业里,技术总会有很多方法变得有用。
文字属性
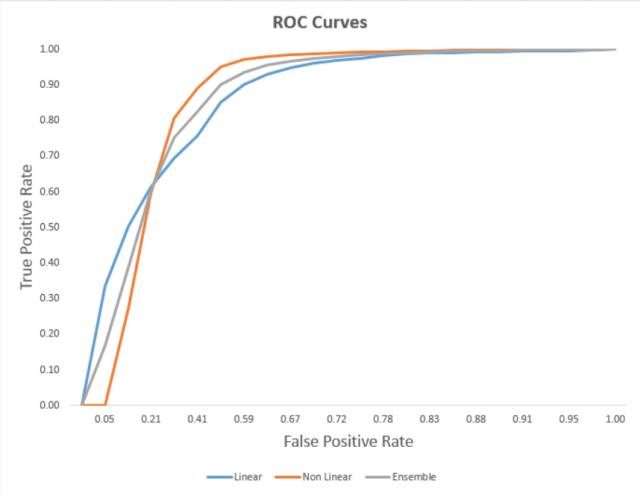
在获得和连接所有属性后,我们对它们运行了许多不同的算法。结果显示最有前途的算法是渐进增长分类器( gradient boosting classifier),脊分类器( ridge classifier)和一个两层的神经网络。
随后,为了迫使我们自己做出更明确的决策,我们设定用来衡量一个网站是否能排进前十的阈值。例如,如果我们预测阈值是 0.85 ,然后如果我们预测网站排进前十的概率高于 0.85 ,我们就认为这个网站将进入前十。
那个时候,我们遇到了才华横溢的巴西数据科学家 Alejandro Simkievich。最有趣的事情是他正在研究搜索领域的相关性和转化率优化(CRO)等问题,并且正在准备参加 Kaggle 竞赛。(Kaggle 是一个针对科学家和机器学习爱好者举办机器学习竞赛的网站)
最终,我们使用简单的平均值将模型结果集中在一起处理,因此我们得到了一些额外收获,因为不同模型倾向于有不同的偏差。
从那点来看,问题转变成二进制(是或否)分类问题,我们只有两个分类:1)网站是排在前十的,2)网站不是排在前十的。此外,我们决定预测一个给定网站属于这两类的概率,而不是做出是或否的预测。
最后一步是设定阈值将概率估算转变为二进制预测(「是的,我们预测此网站位于谷歌排名前十」或「不是的,我们预测此网站不会进谷歌排名前十。」)为了做到这点,我们优化了交叉确认集(cross-validation set ),然后使用了在测试集上得到的阈值。
下面这个图表概述了整个过程:
既然我们有了数据,我们尝试了几种方式预测每个网页的谷歌排名。起初,我们使用回归算法(regression algorithm)。即,我们追求预测在搜索给定的词语时网站的精确排名(比如,搜索词语 Y,预测某网站的排名为 X),但是,在几周之后,我们意识到这项任务太困难了。首先,排名指的是一个网站与其它网站的相对关系,而不是指网站的内在属性。既然我们不可能拿在给定搜索词条件下所有的网站排名去训练我们的算法,我们重新表述了问题。
用 TF-IDF 算法得出的数组是非常稀疏的(对于给定的实例大多数行列的数据是零),所以我们应用降维手段(奇异值分解)减少属性/行列的数量。
挖掘分析并深入了解访客、会话、趋势和潜在可行性的新方法
类别变量
机器学习正快速成为许多大公司不可或缺的工具。确切地说,每个人都听说过谷歌的人工智能算法打败了前世界围棋冠军,还听说过像 RankBrain 这样的技术,但是机器学习无需故作神秘,只在数学研究领域内闭门造车。有许多可以利用的文献资料和技术,它们对于有诸多可以操作的数据的行业都是有用的,给这些行业带来了希望。
我们的目标是最终取得足够数据成功地训练一个模型,而且这意味着我们需要很多数据。对于第一个模型,我们有大约 20 万观测值(行)和 54 个属性(列)。
数字属性指的是该关键词可以表示无限或有限区间内的任意数字。
文字属性显然指文本,包括搜索关键词,网站内容、标题、元数据描述(meta description),锚文本、标题(H1 H2,H3)等。
我确信你听说过「一个坏掉的钟每天有两次能正确指示时间」这句格言。输入每个关键词得到 100 种结果,随意瞎猜总能以 90% 的正确率预测「不能排在前十」的情况。混淆矩阵确保肯定的和否定的答案都是正确的。在我们最好的模型中,我们获得大约 41% 的正确肯定和 41% 的正确否定。
分类算法用于预测诸多可能答案中的一个类别的成员。这可以是简单的「是或否」分类,或者「红、绿或蓝」的分类。如果你需要基于特征预测一个不认识的人是男还是女,你就得选择选择这个模型。它们被称作离散变量。
机器学习是一个即使你不知道它是如何工作的你也能使用的强大工具 。我读了很多关于 RankBrain 和工程师无法理解它是如何工作的文章。这是机器学习神奇和美丽的原因。类似于生命在进化过程中会获得不同的特征一样,机器学习在过程中找到了答案,而不是给出既定的方法。
我们认识到,就谷歌排名而言,最紧要的是在给定搜索词时一个给定的网站是否最终能排在第一页。因而,我们重新剖析了问题:如果我们预测在搜索某个词时一个网站的谷歌排名是否能进前十,又会怎样呢?
在接下来的几段里,我将会带你过一遍我们的实验,我还会讨论一些对 SEO 很重要的技术问题。