快手的推荐系统背后 英特尔做了什么?
大数据时代,个人信息越来越透明,以至于手机APP都能读懂你我的心思,甚至能将信息精准地送达到每一个移动端。APP开发者将其称之为“算法推荐”,商家将其称之为“个性化定制”。有人为推荐机制津津乐道,“原来手机比男朋友更懂我”,听到更多合口味的音乐,看更多爱好的视频;也有人感叹其恐怖,担心陷入算法布局好的陷阱,陷入信息茧房。

价值巨大的推荐系统
虽然我们开始警惕推荐机制可能带来的危害,但对于企业而言,推荐机制蕴藏着巨大的价值,推荐系统的加速不会停止。
根据快手官网数据显示,2015年6月,快手的单日用户上传视频量突破260万;2016年4月总用户数突破3亿。截止目前为止,快手累计200亿条短视频库存,每天仍有超过1500万条视频新增、千亿条视频曝光,早已从一个Gif生成工具蜕变成为一个日活3亿、日播放量200亿的短视频社区。
当构建起庞大的数字世界后,快手需要面对的问题是,如何在承载高峰期每秒数十万并发调用量的同时,从上亿级别的短视频库中,通过千亿参数级别的深度模型向不同的用户对象推送合适的内容,即其推荐系统的加速问题。
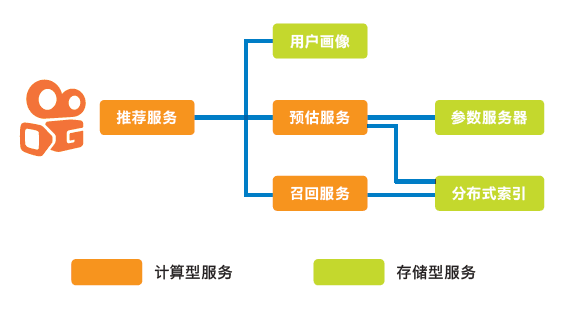
为此,快手基于异构设备构建了计算与存储分离的推荐系统架构。在该架构的内部,主要由两部分任务组成,一部分是包括推荐服务、预估服务、召回服务在内的计算敏感性服务,另一部分是包括用户画像、参数服务器以及分布式服务器索引的存储敏感性服务,这些模块需要实现大容量内存的数据存储及快速的数据访问。
提升训练速度的英特尔Cooper Lake
实际上,推荐系统加速的本质,一方面是人工智能应用的升级,机器需要对图片、视频等信息进行学习和分类;另一方面,则是对存储和访问的进一步需求。
今年6月,英特尔推出的第三代至强可扩展处理器Cooper Lake就是专为当今内置人工智能数据密集型服务而设计的处理器。雷锋网了解到,英特尔第三代可扩展处理器进一步升级了DLBoost深度学习加速技术,同时,在深度学习加速架构下的VNNI神经网络指令支持bfloat16数据格式。与上一代平台Cascade Lake最顶级的CPU 8280相比,在图像分类处理上,Cooper Lake的计算性能提升1.93倍。

在对人工智能的支持上,区别于第二代至强可扩展处理器支持的Int8数据格式和传统的FP32数据格式,bfloat16数据格式是采用16位存取一个数据,包括1个符号位,8个指数和7个尾数位,同时保证了数据的范围和精度。

雷锋网了解到,虽然bfloat16的精度没有FP32的精度高,但是7位尾数对于大多数人工智能的推理计算模型而言,精度已足够使用。英特尔技术人员透露,相比于上一代基于FP32数据格式做训练,VNNI搭配bfloat16能使训练性能提高93%,推理性能提高90%。
Cooper Lake或将是快手加速推荐系统的好选择。
依托傲腾持久内存,加速存储与访问
更好地存储与访问,是快手在加速推荐系统过程中,需要面临的另一个问题。
在传统的存储架构中,大容量持久化存储主要在硬盘或者固态盘中,对于快手的推荐系统而言,尤其是参数服务器和分布式索引服务,从硬盘或固态盘中索引数据,工作量大,时延长。若将索引工作直接在内存中进行,就会降低访问延时,提高推荐系统的响应。
不过,在内存存储金字塔中,金字塔顶端的存储方案,性能高,存储低,单位容量成本高,金字塔低端则是容量大、性能低,成本低的存储方案,存在断层现象,比如常规的DDR4的内存和NAND的闪存,访问的延迟相差1000倍,典型的容量相差100倍,而单位容量的成本相差10倍。这一断层现象导致很多应用在选择方案时,难以找到比较平衡的设计。
基于这一难题,英特尔推出了傲腾持久内存,与上一代产品相比,其内存带宽提升25%,若搭配之后发布Ice Lake的平台,每处理器可带来4.5TB的总内存容量。同时,在做数据写入时,其访问延迟只有几百纳秒,而一个普通的NAND SSD的访问时间则在100微秒左右。
英特尔技术专家介绍,英特尔第三代至强可扩展平台与傲腾持久内存结合,可将服务器上每个节点的容量从原来的几百GB扩展至TB级别,例如一个4路、4个插槽的第三代至强可扩展处理器平台,每个插槽都搭配傲腾持久内存,支持的最大内存就可达到18T。
基于此,快手率先与英特尔展开合作,结合英特尔至强可扩展处理器平台和傲腾持久内存,快手推荐系统性能及TCO得到了优化和提升。不仅大大降低了数据访问延迟时间,还缩短了系统故障恢复时长。
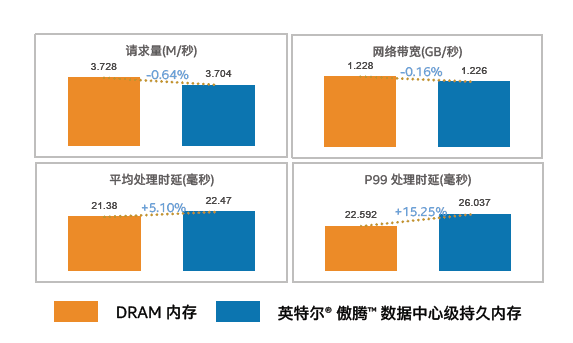
同时,傲腾持久内存与DRAM内存性能表现相似,前者相比于后者更具成本和容量优势。因此在同英特尔的合作中,快手推荐系统的总拥有成本(CTO)降低了30%。
除了在推荐系统方面同英特尔合作,改善存储与访问速度之外,快手也正在同英特尔探讨成立联合实验室,推动业务创新及升级数据中心。
作为推荐系统的受益者,快手或将在进一步加速生态系统的过程中再次尝到甜头。