AI 找星星,发现了50颗

图片来源@unsplash
近日,英国华威大学的大卫·阿姆斯特朗博士(David Armstrong)领导的研究团队开发了一项新的机器学习算法,从美国航空航天局(NASA)的陈旧数据中,识别出太阳系外的行星。他们确认了50颗系外行星的存在,从海王星大小的气体巨行星到比地球还小的岩石世界,无所不包。
方法是,计算出每个行星的成为候选星球的概率。
许多太阳系外行星调查都通过望远镜中的大量数据来搜索行星在望远镜与恒星之间通过的迹象,这就是所谓的过境。这会导致望远镜探测到的恒星发出明显的光线下降,但这也可能是由于来自背景物体的干扰,甚至相机中的微小误差所致。这些误报可以在行星验证过程中筛选出来。

华威大学(Warwick U)物理系和计算机科学系以及艾伦·图灵学院的研究人员建立了一种基于机器学习的算法,该算法可以在NASA的开普勒和TESS等望远镜任务发现的数千个候选行星的大样本中区分出真实的行星和虚假的行星。
AI算法接受了识别真实行星的训练,使用了两大已确认的行星样本和现已退役的开普勒任务的误报。
然后,研究人员在开普勒尚未确认的候选行星数据集上使用了该算法,产生了50个新的确认行星,其中第一个将通过机器学习进行验证。以前的机器学习技术只对候选行星进行排序,但从未自行确定候选行星是否是真正行星的概率,而这是行星验证的必要步骤。

《亲爱的数据》出品
英国华威大学物理系的大卫·阿姆斯特朗博士说:“我们开发的算法可以让我们挑选50个候选行星进行行星验证,并将它们升级为真正的行星。”我们希望将这项技术应用于当前和未来的TESS和PLATO等任务中的大量候选样本。
问题是,第二种方法产生了大量恒星的亮度数据,其中许多恒星不会有可见的系外行星。
于是,人工智能上场了。
阿姆斯特朗博士的学校个人网页上介绍:“我的兴趣之一是将机器学习技术应用于天体物理学问题。与计算机科学部门合作,将最新的机器学习技术应用于太阳系外行星。”

《亲爱的数据》出品
阿姆斯特朗博士,谈道:“就行星验证而言,之前没有人使用过机器学习技术。机器学习已经被用于对候选行星进行排名,但从来没有在概率框架中使用过,而概率框架是你真正验证一颗行星所需要的。我们现在可以说出精确的统计可能性,而不是说哪些候选者更有可能是行星。如果一个候选行星的假阳性概率小于1%,它就被认为是经过验证的行星。”
华威大学的计算机科学系副主任、阿兰·图灵研究所(Alan Turing Institute)研究员Theo Damoulas博士说:

《亲爱的数据》出品
“机器学习,尤其适合这样一个激动人心的问题。
在天体物理学中,需要整合先验知识-阿姆斯特朗博士等专家和量化预测的不确定性。一个典型的例子,当额外的计算复杂性的概率方法取得显著的回报。一旦建立和训练好,该算法比现有的技术更快,而且可以完全自动化,这使得它非常适合分析在当前调查中观察到的潜在的数千个候选行星。
阿姆斯特朗博士补充说:“到目前为止,几乎30%的已知行星仅用一种方法就被验证了,这并不理想。仅仅因为这个原因,开发新的验证方法是可取的。但机器学习也能让我们做得非常快,更快地确定候选人的优先级。”

《亲爱的数据》出品
研究人员认为,它应该是未来用来验证行星的工具之一。
根据新的研究,在所有确认的系外行星中,大约有三分之一是用单一的分析方法确认的,这并不理想。科学家们用已确认身份的系外行星数据和“假行星”的数据来训练神经网络(一种人工智能算法),这样能在新的数据中识别出那些明显的迹象(信号)。
新技术比以前的技术更快,可以自动化,并且可以通过进一步的"训练”加以改进效果。
阿姆斯特朗博士说:“我们仍然需要花时间训练算法,但一旦训练完成,在未来的候选人中应用它就会变得容易得多。你也可以结合新的发现来逐步改进它。像TESS这样的调查预计会有成千上万的行星候选行星,能够一致地分析它们是很理想的。像这样快速、自动化的系统可以让我们用更少的步骤验证行星,让我们做得更有效率。”
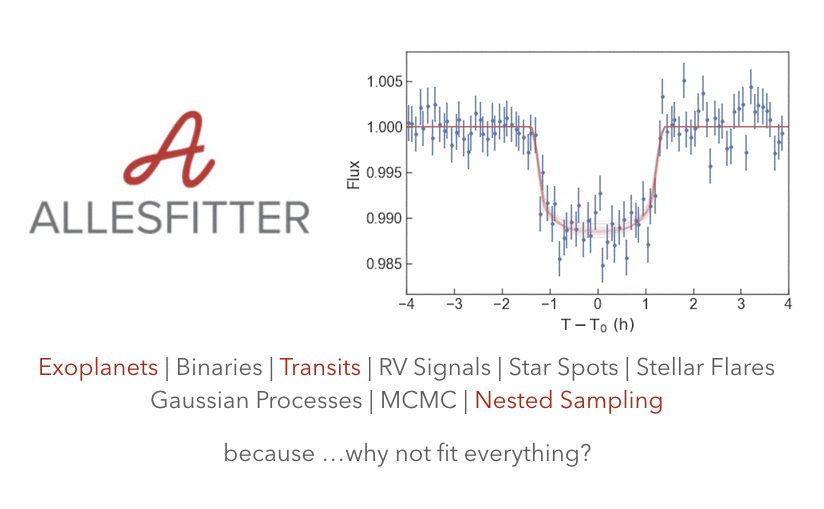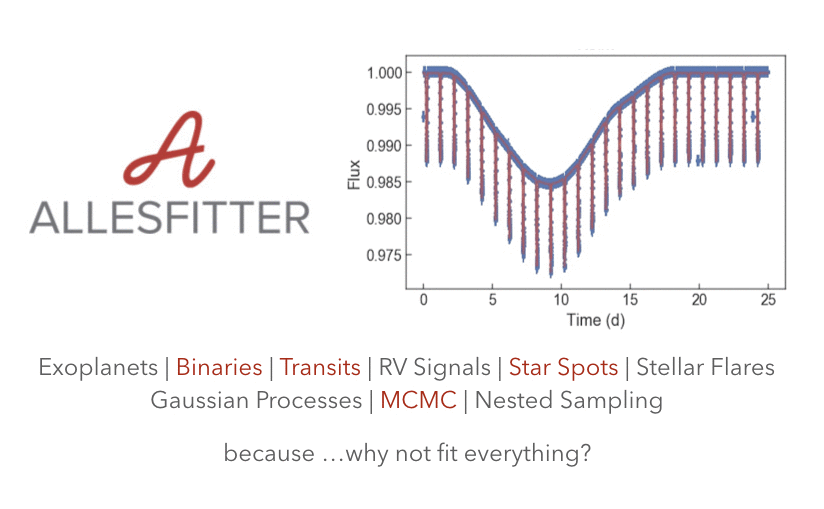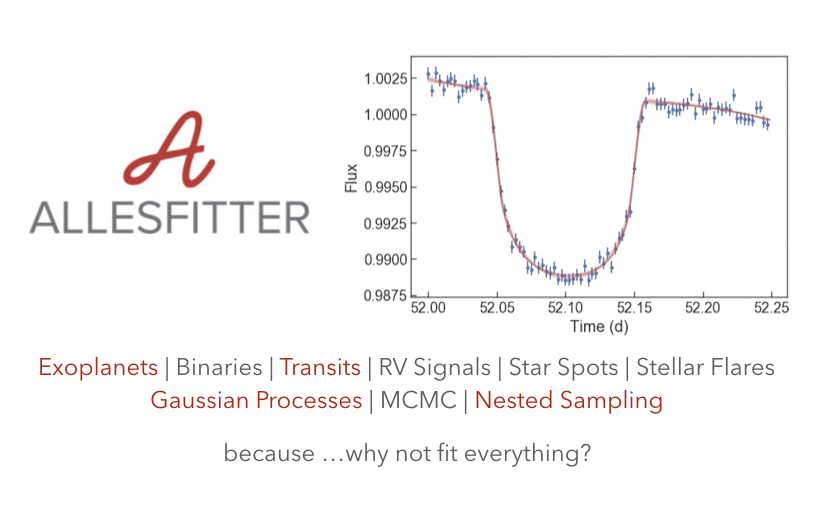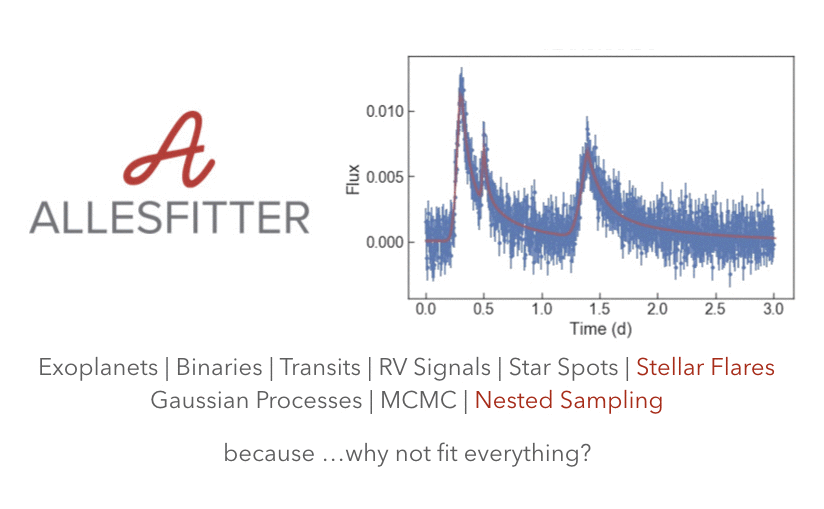
《亲爱的数据》出品
尽管取得了突破,但是,该算法仍处于早期阶段。在陈旧数据中找到错失的金子,提高了人类探索未知宇宙世界的效率。验证行星的新工具问世了,新老方法共同为系外行星探索出力。

