word2vector原理
时间:2020-09-06 10:30:08
作者:重庆seo小潘
来源:
将 word映射到一个新的空间中,并以多维的连续实数向量进行表示叫做“Word Represention” 或 “Word Embedding”。 自从21世纪以来,人们逐渐从原始的词向量稀疏表示法过渡到现在的低维空间中的密集表示。 用稀疏表示法在解决实际问题时经常会遇到维数灾难

将 word映射到一个新的空间中,并以多维的连续实数向量进行表示叫做“Word Represention” 或 “Word Embedding”。
自从21世纪以来,人们逐渐从原始的词向量稀疏表示法过渡到现在的低维空间中的密集表示。
用稀疏表示法在解决实际问题时经常会遇到维数灾难,并且语义信息无法表示,无法揭示word之间的潜在联系。
而采用低维空间表示法,不但解决了维数灾难问题,并且挖掘了word之间的关联属性,从而提高了向量语义上的准确度。
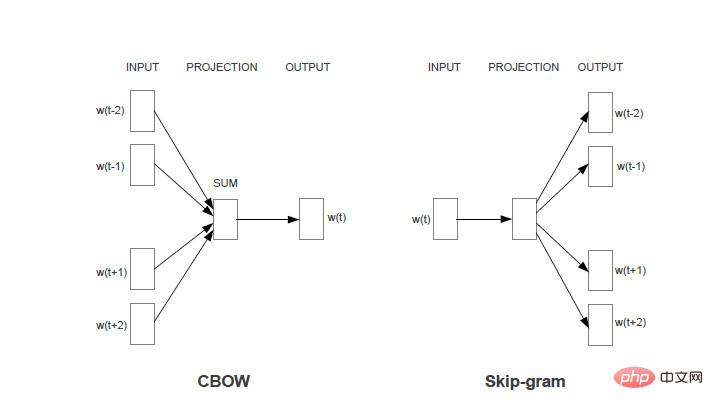
word2vec 的学习任务
假设有这样一句话:今天 下午 2点钟 搜索 引擎 组 开 组会。
任务1:对于每一个word, 使用该word周围的word 来预测当前word生成的概率。如使用“今天、下午、搜索、引擎、组”来生成“2点钟”。
任务2:对于每一个word,使用该word本身来预测生成其他word的概率。如使用“2点钟”来生成“今天、下午、搜索、引擎、组”中的每个word。
两个任务共同的限制条件是:对于相同的输入,输出每个word的概率之和为1。
Word2vec的模型就是想通过机器学习的方法来达到提高上述任务准确率的一种方法。两个任务分别对应两个的模型(CBOW和skim-gram)。如果不做特殊说明,下文均使用CBOW即任务1所对应的模型来进行分析。
Skim-gram模型分析方法相同。
更多Word 相关技术文章,请访问Word教程栏目进行学习!以上就是word2vector原理的详细内容,更多请关注小潘博客其它相关文章!

