NVIDIA RTX 30系列架构详解:8nm安培GPU的两倍性能从何而来?
在当前的显卡市场上,占据80%的NVIDIA公司被玩家爱且恨着——他们带来了最近十多年来最好的显卡,同时也让高端游戏卡的价格高企,发烧显卡至少五位数起。
在RTX 30系列显卡发布之后,玩家的不满似乎释然了,相比当前的图灵显卡,安培架构的RTX 3090/3080/3070显卡一下子变得真香了,因为它们性能翻倍不说,国内价格反而下降了。

·GeForce RTX 3090:取代RTX Titan,相比于Titan RTX快了50%,性能是RTX 2080 Ti显卡的2倍,配备24GB GDDR6X显存,售价11999元,9月24日上市。
·GeForce RTX 3080:取代RTX 2080 Ti,相比于RTX 2080性能快2倍,搭配10GB GDDR6X显存,海外699美元没变,国内从上代6499降至5499元,9月17日上市。
·GeForce RTX 3070:价格不到RTX 2080 Ti的一半,但是平均性能更高,同时比RTX 2070快足足60%,配备8GB GDDR6显存,售价3899元,10月份上市。

RTX 30系列显卡售价及上市时间
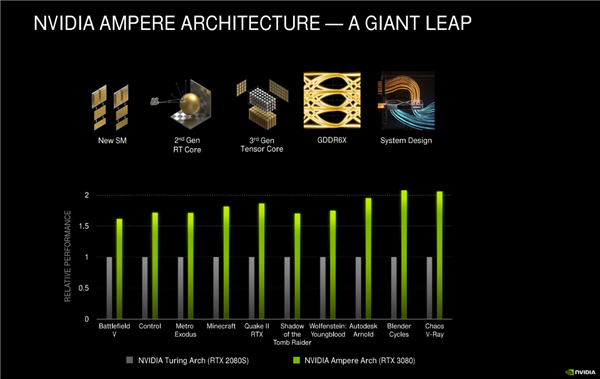
RTX 30系列显卡性能变化
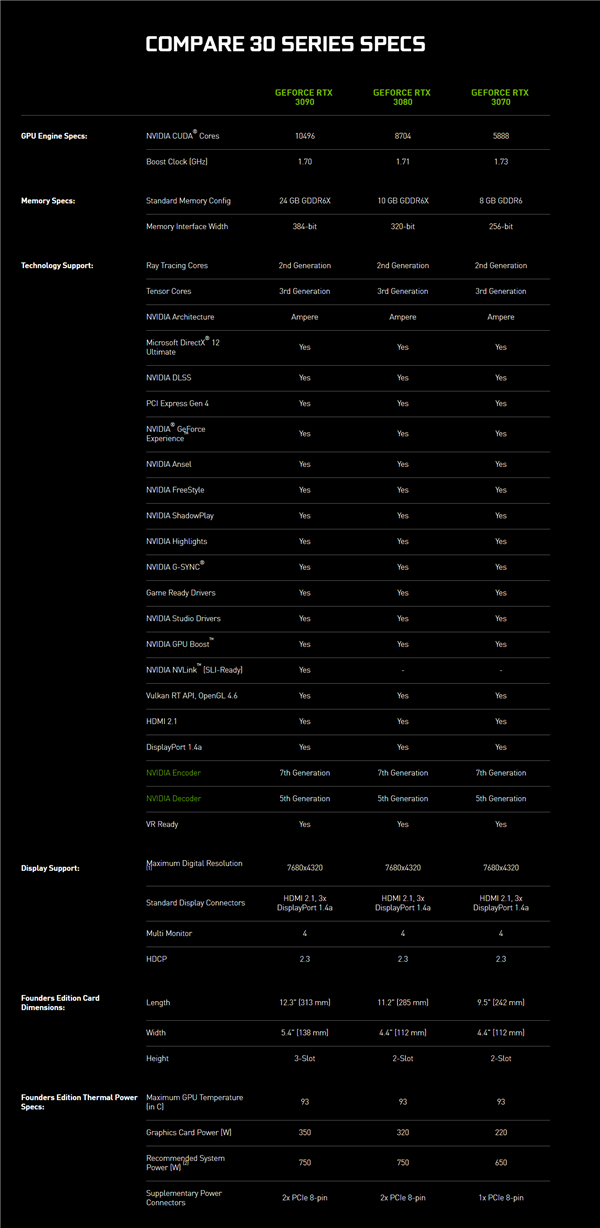
RTX 30系列显卡规格
从这个规格表中可以看出,与RTX 2080 Ti显卡相比,RTX 3090的标志性FP32性能从13.4T提升到了35.7T,翻倍还多,光追及AI加速提升也同样明显。
与图灵显卡相比,安培GPU的变化之大让人惊讶,在过去十多年的显卡升级换代中,性能翻倍的提升很少见到了,NVIDA是怎么做到的?
今天我们就来从详细解读一下安培GPU的架构,探究它到底带来了哪些技术升级以致于让NVIDIA创始人黄仁勋称之为有史以来性能提升最大的一次。
先从工艺说起:12nm干掉7nm之后 8nm如何再进一步
对于半导体芯片来说,很关键的一部分是制程工艺,先进的架构也要通过工艺来实现,这是影响芯片能效、性能甚至成本的一大因素。
对NVIDIA来说,他们的Volta伏特、Turing图灵两代架构都是台积电12nm FFN工艺了,这是台积电16nm工艺的改进版,如果再算上16nm的Pascal架构,实际上过去三代GPU都没有重大工艺上的升级了。
在Ampere安培架构上,NVIDIA终于升级工艺了,只不过这次有两个意外——首先没有选择台积电,其次没有上7nm,而是三星定制的8nm工艺,虽然跟7nm看起来只差了1nm,但实际上是两代工艺。
考虑到NVIDIA之前对工艺的表态,没用7nm工艺而是三星8nm工艺又在意料之中,最关键的问题在于NVIDIA能够做到多好。
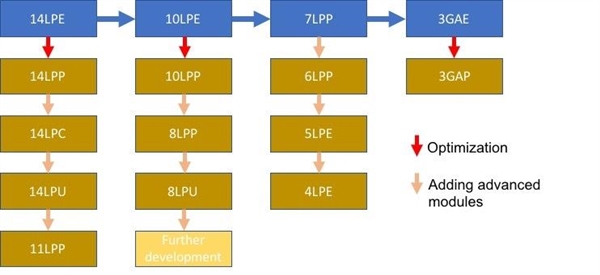
三星的8nm工艺是基于10nm工艺改良的,至少有LPP和LPU两个版本,前者适合移动SoC,后者适合高性能芯片,NVIDIA的定制大概是基于后者。
与台积电的7nm工艺晶体管密度大约1亿/mm2相比,8nm工艺大概是6000万晶体管/mm2,但这是单一的SRAM芯片的对比,实际上GPU芯片比较复杂,差距会缩小很多。
根据是NVIDIA公布的信息,台积电7nm工艺制造的安培A100核心是540亿晶体管,核心面积826mm2,而三星8nm工艺制造的GA102核心是280亿晶体管,核心面积官方没公布,据悉是628mm2,也是大核心了。
这么算下来,7nm A100核心的晶体管密度6560万晶体管/mm2,而三星8nm的GA102核心也有4460万晶体管/mm2——差距仍在,但似乎可以接受了。
三星8nm工艺的晶圆代工价格还是秘密,但是不论技术还是商业策略上,三星都会比台积电便宜很多,预计代工价格能差30%或者更高,所以这也是RTX 30系列显卡能够不涨价甚至降价的关键。
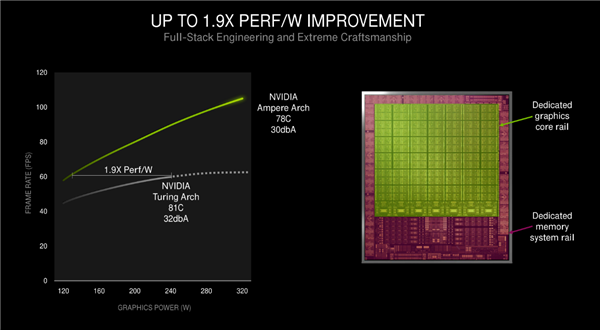
那三星8nm工艺带来了多大的性能及能效提升呢?首先大家可以看到RTX 30系列显卡的频率提升了,从RTX 20系列的1.5GHz+提升到了1.7GHz+,升级工艺还是有性能提升的。
不过RTX 20系列的加速频率实际可以达到1.9GHz甚至接近2GHz,RTX 30系列预计也就这个水平。
但是能效还是有提升的,NVIDIA官方称在60fps性能下,图灵显卡的功耗大约有240W,安培显卡则是120W多点,算下来是1.9倍能效,提升了90%,同时温度还低了3度,噪音减少2分贝。
总的来说,在工艺这方面大家对安培GPU有惊喜有失望,失望的是没有上预期中的7nm工艺(不管台积电还是三星),工艺依然升级到了8nm。
但是NVIDIA工艺虽然并不算激进,但性能、能效进步还是挺大的,安培显卡各方面指标都是大幅胜过现在的图灵卡,而且价格做到了不升反降,这也是不追求激进工艺的好处,反正之前12nm都能赢,现在上8nm更加稳妥了。
安培GPU架构详解之:FP32单元翻倍 CUDA核心改了什么?
发布安培的时候,NVIDIA CEO黄仁勋表示这是GPU有史以来最大的性能飞跃,而2018年推出图灵GPU时,老黄也是类似的说词——GPU有史以来最大的变革,这两个评价其实也没错。
图灵GPU架构有很多第一次,首次支持RTX Core(光追加速单元),首次支持Tensor Core,同时还改进了CUDA内核,不过前两个是重点。

在安培GPU上,RT Core、Tensor Core当然继续加强,不过最主要的亮点是CUDA架构的改进,性能翻倍的根源就在这里,我们先来看看这方面的变化。

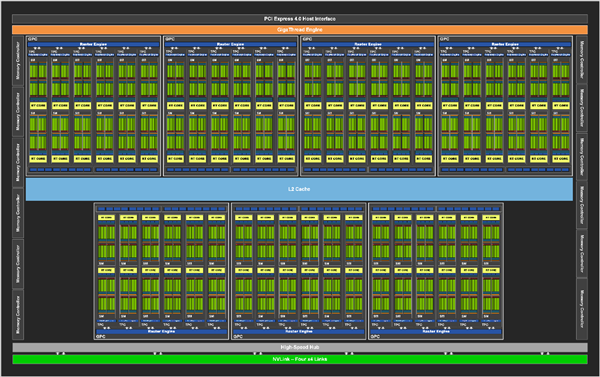
GA102核心架构示意图
GA102核心总计7组GPC单元,每组有12组SM单元,总计84组,RTX 30系列显卡视乎规格不同启用的SM单元总数不同,RTX 3090是82组,RTX 3080是68组,RTX 3070是46组。
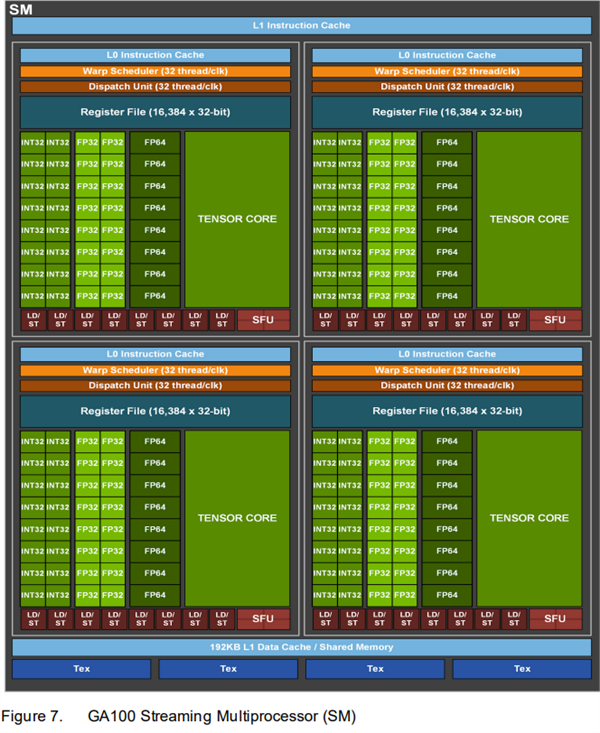
在之前的GA100大核心中,每组SM是64个INT32单元、64个FP32单元及32个FP64单元组成的,但在GA102核心中,FP64单元大幅减少,增加了RT Core,Tensor Core也略微减少。
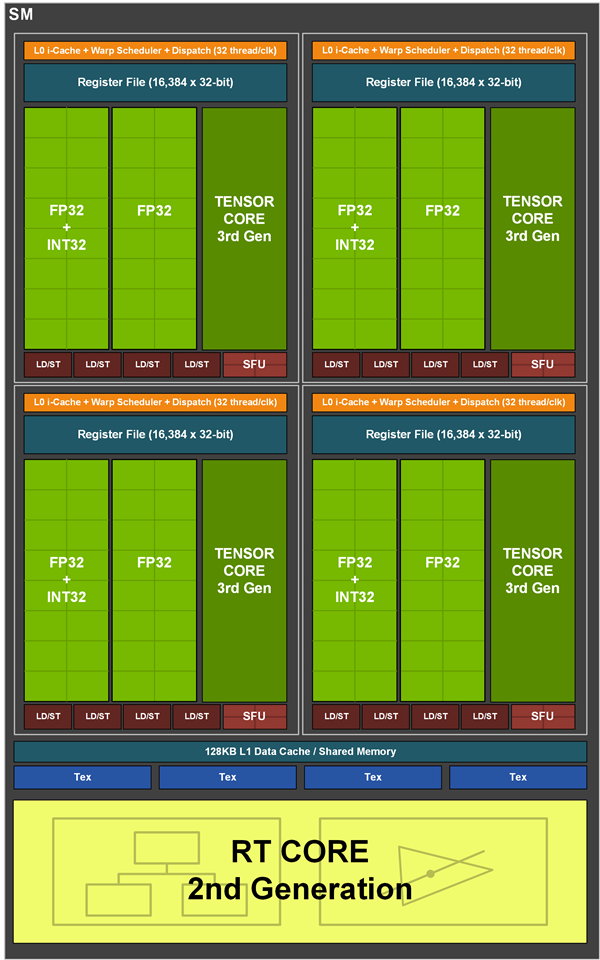
GA102核心的SM单元
按照之前图灵GPU的路线走,安培GPU的SM单元增加的并不多,但实际上FP32性能翻倍了还多,算上频率,RTX 3080的理论性能差不多是RTX 2080的三倍了,这是怎么做到的?
答案就是CUDA核心的FP32翻倍,但翻倍的方式有点特殊,每个SM单元中有4个分区,每个分区除了第三代Tensor Core核心之外,还有一组是16个FP32单元及16个FP32、16个IN32组成的单元,后者可以同时执行FP32或者INT32运算。
16个FP32单元每周期可执行16个FP32运算,混合的那个单元可以执行32个FP32或者16个FP32+16个INT32。
如此一来,每个SM单元可以同时执行4x(16FP32+16FP32)=128个FP32运算,或者4x(16FP32+16INT32)=64个FP32+64个INT32运算。
只算FP32浮点的话,那么就是浮点翻倍了,因为图灵以及GA100都是每周期64个FP32浮点而已,现在可以做128个FP32运算了。

提升FP32性能不论对游戏还是运算都大有裨益,但也需要配套的提升,GA102的L1容量提升了33%,L1带宽从116GB/s翻倍到219GB/s,共享内存的性能也从每周期64B翻倍到128B。

安培GPU架构详解之:RTX光追升级 从能用到好用
上代的图灵GPU架构最大的亮点就是引入了RTX实时光追技术,开启了3D游戏的光追时代,意义重大。
但是先行者的代价也不小,而且图灵GPU的光追效果在实际游戏中并不明显,对性能的影响颇大,第一代RTX光追只能说解决了有无问题,现在的安培GPU才是RTX光追更好用。

在图灵GPU上,NVIDIA使用的第一代RT Core可以提供10Giga Rays/s的性能,而在安培GPU上,RT Core升级到了第二代,号称性能翻倍,仅此一点就可以大幅提升光追性能了。
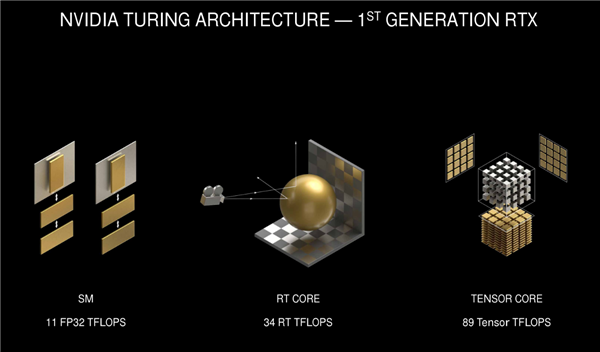
图灵GPU光追架构

安培GPU光追
不过这还不够,在安培GPU上,参与光追应用加速的不只是SM单元、RT单元了,第三代Tensor Core单元也更多的参与其中,而安培架构中SM、RT、Tensor单元的性能都是大幅提升的,以RTX 3080为例,SM单元性能11T提升到了30T,RT性能从上代34T提升到了58T,Tensor性能从89暴涨到238T.
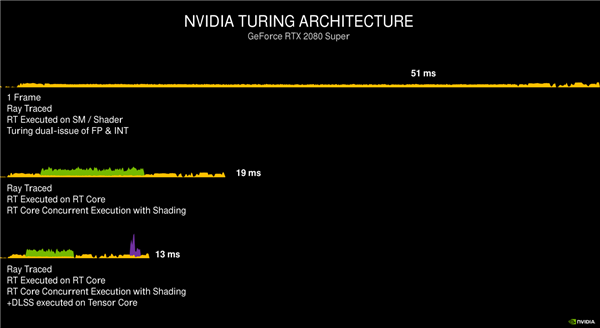
这带来的一个结果就是光追性能大幅提升,不支持硬件加速的Pascal GPU渲染一帧要51ms,图灵可以提升到19ms,加上DLSS等可以缩短到13ms,已经大大低于60fps所需的16.6ms帧时间了。

在安培GPU上,时间还可以更快,单纯硬件加速就可以从13ms缩短到7.5ms,加上第二代技术的加成就只有6.7ms了。

总之,在RT光追性能上,不说没有硬件加速的Pascal显卡,对比RTX 2080到RTX 3080的变化,软件渲染的性能提升了40%,硬件加速的话提升70%,硬件加速+DLSS也提升了70%,再加上其他技术的辅助,最高可以提升90%的光追性能。
目前还没有实际评测解禁,具体游戏中的提升还不好说,但是刨去官方测试的理想状态,光追性能提升个50%应该无压力,这足以让当前的光追游戏更具实用性,不再是开了RTX性能就大幅下降的情况了。
至于我们可以预期,以前1080p 30fps运行的光追游戏在今年可以实现1080p 60或者2K 144流畅运行了,可用性至少提高一个等级,从凑合能用变得更好用了。
安培GPU架构详解之:第三代Tensor Core、8K游戏成为可能
Tensor Core是伏特GPU引入的一种新核心,现在也是SM单元的三大子核心之一,不过在数据中心GPU上,AI加速功能非常重要,所以A100大核心的Tensor Core占据了相当大的面积,功能及性能都改进不少。
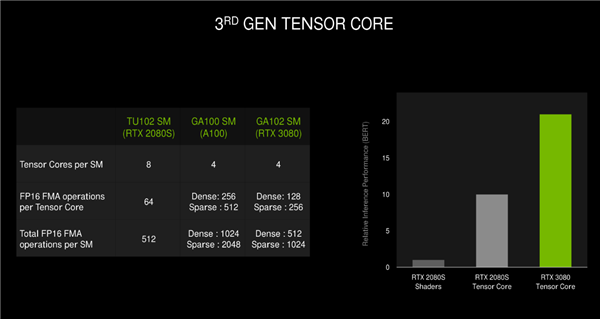
在GA102核心中,Tensor Core也是第三代架构的,但是跟GA100核心的还是有所不同,每组SM单元也是4个Tensor Core,但是性能减半。
但在游戏GPU上,Tensor Core的意义没那么大了,NVIDIA官方的应用中DLSS算是发挥AI加速比较好的,可以进一步提升游戏性能,这一次虽然还是DLSS 2.0,但是配合RTX 3090显卡强大的性能,8K DLSS游戏成为可能。
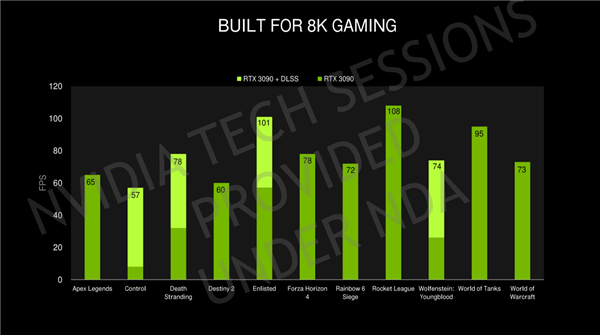
8K游戏的分辨率是4K的4倍了,是1080p的16倍,光是高分辨率带来的挑战就足以让当前的高端硬件吃不消了,但在DLSS的加持下,RTX 3090在多款主流游戏中可以实现60fps以上的性能,最高可以超过100fps,可玩性已经不是问题。
这大概就是Tensor Core对游戏的重要意义,不过我们得说8K现在还比较遥远,性能跟上了硬件设备也跟不上,现在能玩好4K就差不多了。
安培GPU架构详解之:升级GDDR6X显存 带宽堪比HBM2
除了GPU本体之外,显存技术这一代也升级了,上代的图灵GPU首发了GDDR6显存,这一次NVIDIA又迅速商业化了GDDR6X显存,其中RTX 3090不仅频率飙上了19.5Gbps,还达到了24GB超大容量。
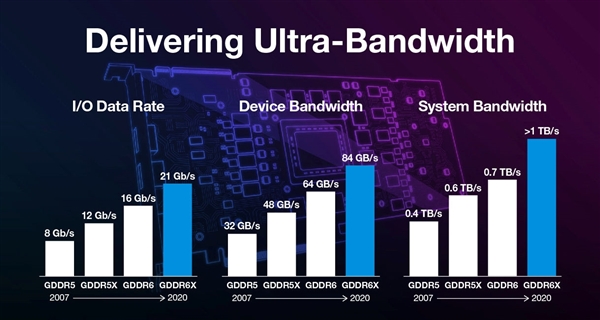
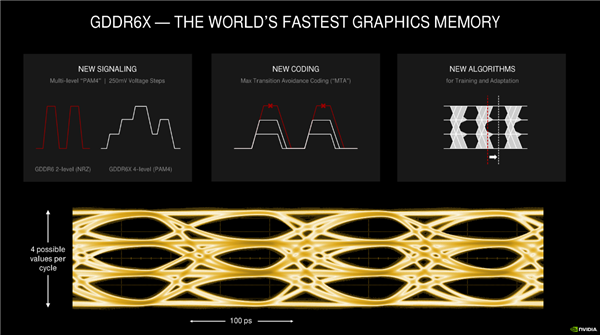
GDDR6X基于目前的GDDR6升级而来,基本架构和技术保持不变,重点加入了PAM4信令机制,在处理器和内存之间,使用四档电压,每个周期内编码和传输两个比特位。
对于PAM4机制,大家可以理解为闪存从SLC到MLC的升级,每周期传输的数据量可以翻倍,因此实现了超高速率的等效频率,起步就可以做到21Gbps,NVIDIA目前使用的略微保守,RTX 3090是19.2Gbps,RTX 3080是18Gbps。
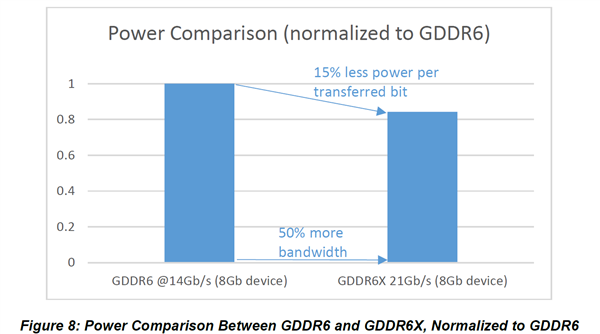
使用GDDR6X显存之后,在等效带宽提升50%的情况下,能效也提升了,每bit功耗降低了15%。
但是想象一下,如今GDD6X就可以实现HBM2显存的1TB/s带宽,但又不需要后者那么复杂的工艺和成本,在消费级显卡上真的可以不需要考虑HBM2了。
安培GPU架构详解之:视频解码、接口、PCIe 4.0
在安培GPU上,还有一些其他技术升级,这里简单说一下吧:
·AV1视频解码升级 支持8K

8K是NVIDIA这次升级的一个重要,除了游戏性能可以支持8K之外,接口及解码上也做了准备。
首先,安培GPU更新的NVDEC首次实现了AV1的8K 60p解码支持,这个编码比H264能够节省大量带宽,但CPU软解的话,9900K这样的CPU占用率也要达到85%,而安培GPU的NVDEC硬解占有率只有4%,同时帧速能从28fps达到60fps,流畅度也提升了。
·首发HDMI 2.1接口、8K输出

输出接口方面,除了3个DP1.4a接口之外,这次首发了HDMI 2.1接口,支持4屏输出,48Gbps的新接口可以实现8K 60Hz HDR支持,适合搭配新一代显示器。
·支持PCIe 4.0 不用担心性能损失
RTX 30系列显卡还支持了PCIe 4.0,这也是大势所趋了,不过PCIe 4.0的问题在于只有AMD的X570平台才能完整支持,Intel的桌面平台还没支持的,有些尴尬。
玩家可以考虑搭配AMD的锐龙平台,但也不必为了PCIe 4.0强行搭配,NVIDIA表示PCIe 4.0降回PCIe 3.0对性能影响有限,只有几个百分点,还不如CPU的影响大,言外之意就是该用酷睿i9-9900K或者酷睿i9-10900K的继续。
游戏工具升级:Reflex、Broadcast、Omniverse Machinima
这几年中NVIDIA在显卡市场份额不断提升,不仅仅跟显卡的性能、功耗有关,他们在软件及体验上也着墨不少,GFE中集成了多个备受游戏玩家欢迎的工具,比如Ansel、Highlights等等。
在安培显卡上,NVIDIA这次又带来了三项新功能,包括降低延迟的NVIDIA Reflex、AI加速的直播NVIDIA Broadcast以及NVIDIA Omniverse Machinima。
·NVIDIA Reflex:延迟再降50%
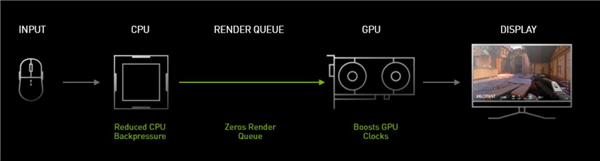
游戏玩家,特别是网络游戏对延迟很敏感,这个延迟不仅仅跟网络、显卡性能有关,还跟系统有关,包括键鼠的输入延迟等。
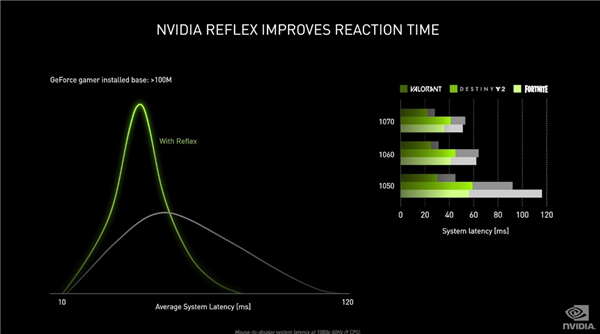
NVIDIA Reflex就是一款可以降低延迟的工具,在支持该技术的游戏中,如《Apex英雄》、《使命召唤:战区》、《堡垒之夜》、《VALORANT》等热门电竞游戏,可将延迟降低50%。
此外,NVIDIA Reflex未来还会有个Reflex延迟分析器(Reflex Latency Analyzer),它可监测鼠标点击,并测量屏幕上相应像素变化所需的时间,比如枪焰闪光,效果堪比超过7000美元的专用高速摄像机和设备。
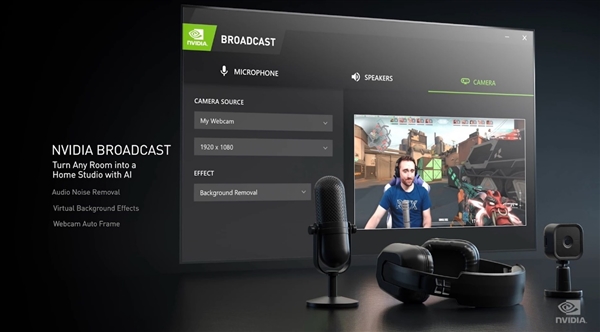
·NVIDIA Broadcast:游戏主播的好帮手
如今游戏跟直播息息相关,NVIDIA Broadcast软件可以让游戏主播更加轻松省力,它通过显卡的AI加速实现了多种功能,比如噪音消除、虚拟背景、自动框显,从而提升麦克风和网络摄像头的效果。
·NVIDIA Omniverse Machinima:自己拍大片
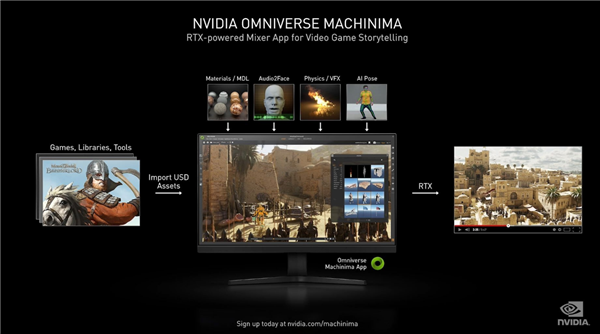
Omniverse Machinima一款引擎电影工具,它可以让玩家利用游戏中的资源自己拍电影,精确地模拟光线、实物、材料和人工智能,并且可以适用于大部分第三方设计工具,如3DS、Max、Maya、Photoshop、Epic Unreal和Rhino等,最终使用RTX系列显卡渲染出电影级的效果。它也是游戏开发商制作游戏CG的利器,显著简化制作游戏过场动画的流程。
One More Thing:RTX IO或许是下一个规则改变者
有关NVIDIA的安培GPU架构及技术上的介绍差不多了,不过最后这一点留给一个看似不起眼但有可能改变游戏体验的新技术——RTX IO,它可以让SSD硬盘实现游戏近乎实时加载的体验。

SSD硬盘现在差不多普及了,它超快的性能也让游戏玩家受益不少,游戏加载速度大幅提升,不过这还没到头,随着游戏容量越来大,数据读取越来越频繁,SSD的性能并不能完美发挥出来。
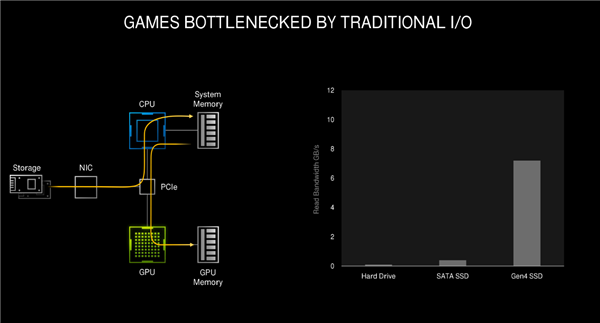
导致这一问题的根源就在于传统的IO设计,经过压缩的游戏数据需要经过硬盘、主控、PCIe、CPU、GPU及各自的内存系统,过程比较繁琐,存在瓶颈可能。
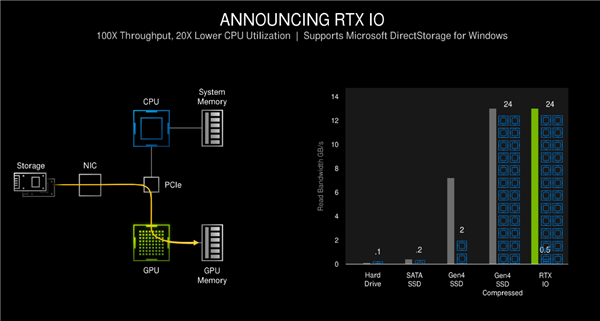
有了RTX IO之后,游戏数据就不需要经过CPU和内存了,直接让GPU读取,并且支持无损解压缩,使得CPU占用率低了20倍,吞吐量提升了100倍。
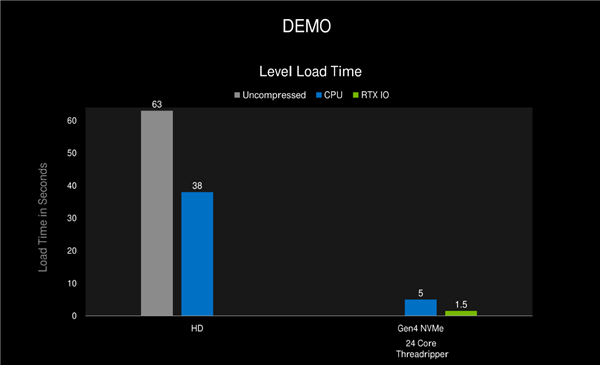
最终带来的好处就是游戏加载速度大幅提升,如上图所示,不说HD硬盘的38秒加载时间,PCIe 4.0硬盘加速也要5秒,但RTX IO技术只要1.5秒即可。
1秒多的时间在感觉上差不多就是实时加载了,一眨眼的功夫就完成了切换,游戏中地图或者场景切换极为迅捷。
NVIDIA的RTX IO技术其实跟新一代主机中的技术差不多,但支持更多的压缩格式,同时在解压缩上也更有效率。它也支持微软的DirectStorage,后者预计也会在2021年登陆Windows 10平台,让主机及PC都能享受到这一技术。

