tcp粘包问题怎么处理?

tcp粘包问题处理的方法:
1、设计方案一:定长发送
在进行数据发送时采用固定长度的设计,也就是无论多大数据发送都分包为固定长度(为便于描述,此处定长为记为LEN),也就是发送端在发送数据时都以LEN为长度进行分包。这样接收方都以固定的LEN进行接收,如此一来发送和接收就能一一对应了。分包的时候不一定能完整的恰好分成多个完整的LEN的包,最后一个包一般都会小于LEN,这时候最后一个包可以在不足的部分填充空白字节。
当然,这种方法会有缺陷。
1.最后一个包的不足长度被填充为空白部分,也即无效字节序。那么接收方可能难以辨别这无效的部分,它本身就是为了补位的,并无实际含义。这就为接收端处理其含义带来了麻烦。当然也有解决办法,可以通过增添标志位的方法来弥补,即在每一个数据包的最前面增加一个定长的报头,然后将该数据包的末尾标记一并发送。接收方根据这个标记确认无效字节序列,从而实现数据的完整接收。
2.在发送包长度随机分布的情况下,会造成带宽浪费。比如发送长度可能为 1,100,1000,4000字节等等,则都需要按照定长最大值即4000来发送,数据包小于4000字节的其他包也会被填充至4000,造成网络负载的无效浪费。
综上,此方案适在发送数据包长度较为稳定(趋于某一固定值)的情况下有较好的效果。
2、设计方案二:尾部标记序列
在每个要发送的数据包的尾部设置一个特殊的字节序列,此序列带有特殊含义,跟字符串的结束符标识”�”一样的含义,用来标示这个数据包的末尾,接收方可对接收的数据进行分析,通过尾部序列确认数据包的边界。
这种方法的缺陷较为明显:
1.接收方需要对数据进行分析,甄别尾部序列。
2.尾部序列的确定本身是一个问题。什么样的序列可以向”�”一样来做一个结束符呢?这个序列必须是不具备通常任何人类或者程序可识别的带含义的数据序列,就像“�”是一个无效字符串内容,因而可以作为字符串的结束标记。那普通的网络通信中,这个序列是什么呢?我想一时间很难找到恰当的答案。
3、设计方案三:头部标记分步接收
这个方法是作者有限学识里最好的办法了。它既不损失效率,还完美解决了任何大小的数据包的边界问题。
这个方法的实现是这样的,定义一个用户报头,在报头中注明每次发送的数据包大小。接收方每次接收时先以报头的size进行数据读取,这必然只能读到一个报头的数据,从报头中得到该数据包的数据大小,然后再按照此大小进行再次读取,就能读到数据的内容了。
这样一来,每个数据包发送时都封装一个报头,然后接收方分两次接收一个包,第一次接收报头,根据报头大小第二次才接收数据内容。(此处的data[0]的本质是一个指针,指向数据的正文部分,也可以是一篇连续数据区的起始位置。因此可以设计成data[user_size],这样的话。)
下面通过一个图来展现设计思想。
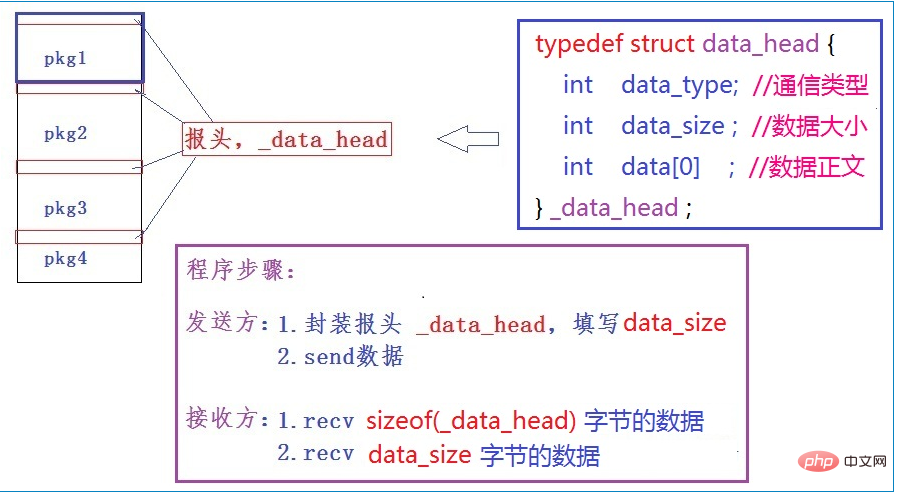
由图看出,数据发送多了封装报头的动作;接收方将每个包的接收拆分成了两次。
这方案看似精妙,实则也有缺陷:
1.报头虽小,但每个包都需要多封装sizeof(_data_head)的数据,积累效应也不可完全忽略。
2.接收方的接收动作分成了两次,也就是进行数据读取的操作被增加了一倍,而数据读取操作的recv或者read都是系统调用,这对内核而言的开销是一个不能完全忽略的影响,对程序而言性能影响可忽略(系统调用的速度非常快)。
优点:避免了程序设计的复杂性,其有效性便于验证,对软件设计的稳定性要求来说更容易达标。综上,方案三乃上上策!以上就是tcp粘包问题怎么处理?的详细内容,更多请关注小潘博客其它相关文章!

