redis缓存怎么和数据库同步
缓存数据与持久化数据的一致性,这个问题总结了一下(看到了一个不错的博文),其实就是读和写,还有就是要注意谁先谁后的问题。

从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。(推荐学习:Redis视频教程)
也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key-value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了python,Ruby,Erlang,PHP客户端,使用很方便。
按照我们一般的使用Redis的场景应该是这样的:

也就是说:我们会先去redis中判断数据是否存在,如果存在,则直接返回缓存好的数据。而如果不存在的话,就会去数据库中,读取数据,并把数据缓存到Redis中。
适用场合:如果数据量比较大,但不是经常更新的情况(比如用户排行)
而第二种Redis的使用,跟第一种的情况完成不同,具体的情况请看:
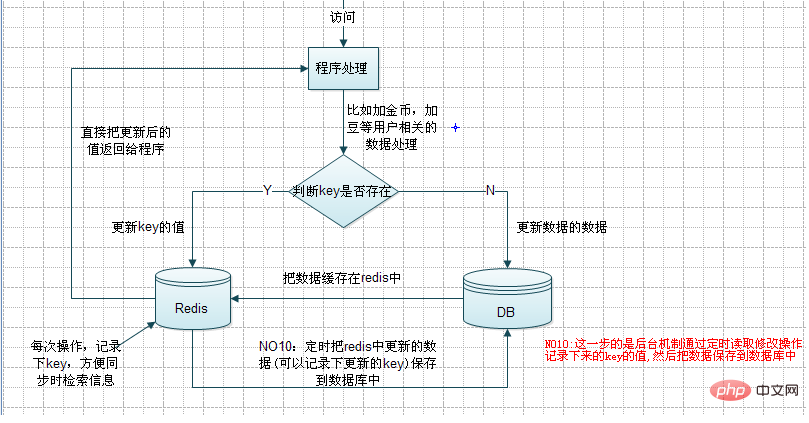
这里我们会先去redis中判断数据是否存在,如果存在,则直接更新对应的数据(这一步会把对应更新过的key记录下来,比如也保存到redis中比如:key为:save_update_keys【用lpush列表记录】),并把更新后的数据返回给页面。而如果不存在的话,就会去先更新数据库中内容,然后把数据保存一份到Redis中。
NO10这步:后面的工作:后台会有相关机制把Redis中的save_update_keys存储的key,分别读取出来,找到对应的数据,更新到DB中。
优点:这个流程的主要目的是把Redis当作数据库使用,更新获取数据比DB快。非常适合大数据量的频繁变动(比如微博)。
缺点:对Redis的依赖很大,要做好宕机时的数据保存。(不过可以使用redis的快照AOF,快速恢复的话,应该不会有多大影响,因为就算Redis不工作了,也不会影响后续数据的处理。)
难点:在前期规划key的格式,存储类型很重要,因为这会影响能否把数据同步到DB。以上就是redis缓存怎么和数据库同步的详细内容,更多请关注小潘博客其它相关文章!

