MySQL大数据查询性能优化教程(图)
MySQL性能优化包括表的优化与列类型选择,表的优化可以细分为什么?1、定长与变长分离;2、常用字段与不常用字段要分离;3、在1对多,需要关联统计的字段上添加冗余字段。
一、表的优化与列类型选择
表的优化:
1、定长与变长分离
如 id int,占4个字节,char(4)占4个字符长度,也是定长,time即每一单元值占的字节是固定的。
核心且常用字段,宜建成定长,放在一张表。
而varchar,text,blob这种变长字段,适合单放一张表,用主键与核心表关联起来。
2、常用字段与不常用字段要分离
需要结合网站具体的业务来分析,分析字段的查询场景,查询频率低的字段,单拆出来。
3、在1对多,需要关联统计的字段上添加冗余字段。
看如下的效果:
每个版块里,有N条帖子,在首页显示了版块信息和版块下的帖子数。
这是如何做的

如果board表只有前2列,则需要取出版块后,
再查post表,select count(*) from post group by board_id,得出每个版块的帖子数。
二、列类型选择
1、字段类型优先级
整型>date
time>enum
char>varchar>blob,text
整型:定长,没有国家/地区之分,没有字符集的差异。比如:
tinyint 1,2,3,4,5 <--> char(1) a,b,c,d,e
从空间上,都占1个字节,但是 order by 排序,前者快。原因,或者需要考虑字符集与校对集(就是排序规则);
time定长,运算快,节省空间。考虑时区,写sql时不方便 where > `2018-08-08`;
enum,能起到约束的目的,内部用整型来存储,但与cahr联查时,内部要经历串与值的转化;
char定长,考虑字符集和(排序)校对集;
varchar不定长,要考虑字符集的转换与排序时的校对集,速度慢;
text/blob 无法使用内存临时表(排序等操作只能在磁盘上进行)
附:关于date/time的选择,大师的明确意见,直接选 int unsgined not null,存储时间戳。
例如:
性别:以utf8为例
char(1) ,3个字长字节
enum('男','女'); 内部转成数字来存,多一个转换过程
tinyint(), 定长1个字节
2、够用就行,不要慷慨(如 smallint varchar(N))
原因:大的字节浪费内存,影响速度。
以年龄为例 tinyint unsigned not null,可以存储255岁,足够。用int浪费了3个字节;
以varchar(10),varchar(300)存储的内容相同,但在表联查时varchar(300)要花更多内存。
3、尽量避免用NULL()
原因:NULL不利于索引,要用特殊的字符来标注。
在磁盘上占据的空间其实更大(MySQL5.5已对null做的改进,但查询仍是不便)
三、索引优化策略
1、索引类型
1.1 B-tree索引
名叫btree索引,大的方面看,都用的平衡树,但具体的实现上,各引擎稍有不同,比如,严格的说,NDB引擎,使用的是T-tree.
但抽象一下 B-tree系统,可理解为“排好序的快速查询结构”。
1.2 hash索引
在memory表里默认是hash索引,hash的理论查询时间复杂度为O(1)。
疑问:既然hash的查找如此高效,为什么不都用hash索引?
回答:
1、hash函数计算后的结果,是随机的,如果是在磁盘上放置数据,以主键为id为例,那么随着id的增长,id对应的行,在磁盘上随机放置。
2、无法对范围查询进行优化。
3、无法利用前缀索引,比如在btree中,field列的值“helloworld”,并加索引查询 x=helloworld自然可以利用索引,x=hello也可以利用索引(左前缀索引)。
4、排序也无法优化。
5、必须回行,就是说通过索引拿到数据位置,必须回到表中取数据。
2、btree索引的常见误区
2.1 在where条件常用的列上加索引,例如:
where cat_id = 3 and price>100;查询第三个栏目,100元以上的商品。
误区:cat_id 上和price上都加上索引。
错:只能用上cat_id 或 price索引,因为是独立的索引,同时只能用一个。
2.2 在多列上建立索引后(联合索引),查询哪个列,索引都会将发挥作用
误区:多列索引上,索引发挥作用,需要满足左前缀要求。
以 index(a,b,c) 为例,(注意和顺序有关)
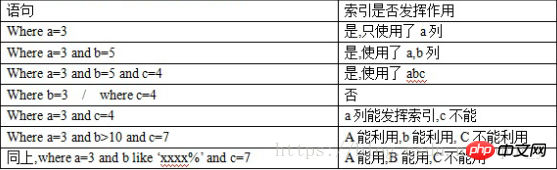
四、索引实验
例如:select * from t4 where c1=3 and c2 = 4 and c4>5 and c3=2;
用到了哪些索引:
explain select * from t4 where c1=3 and c2 = 4 and c4>5 and c3=2 G
如下:
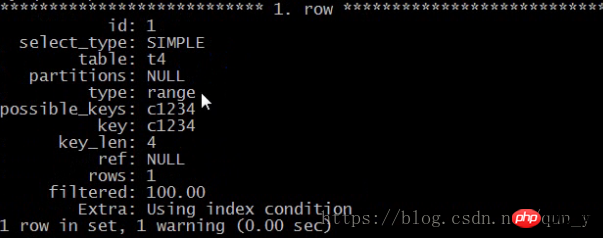
注:(key_len : 4 )
五、聚簇索引与非聚簇索引
Myisam与innodb引擎,索引文件的异同
Myisam:由news.myd和new.myi两个文件,索引文件和数据文件是分开的,叫非聚簇索引。主索引和次索引都指向物理行(磁盘的位置)
innodb:索引和数据是聚在一起的,所以是聚簇索引。innodb的主索引文件上直接存放该行数据,次索引指向对主键索引的引用。
注意:innodb来说:
1、主键索引 即存放索引值,又在叶子中存储行的数据。
2、如果没有主键(primary key),则会unique key做主键。
3、如果没有unique,则系统生成一个内部的rowid做主键。
4、像innodb中,主键的索引结构中,即存储了主键值又存储了行数据,这种结构称为聚簇索引。
聚簇索引
优势:根据主键查询条目比较少时,不用回行(数据就在主键节点下)
劣势:如果碰到不规则数据插入时,造成频繁的页分裂
相关文章:
Mysql 性能优化
相关视频:
MySQL优化视频教程以上就是MySQL大数据查询性能优化教程(图)的详细内容,更多请关注小潘博客其它相关文章!
