一文看懂AB测试
企业为了取得不断的发展,需要不断做出行之有效的策略。而为了找到这些策略,企业需要不断的提出假设和验证假设。AB测试,是验证假设的好方法。这篇文章,我们就给大家详细讲讲AB测试,彻底看懂AB测试。实验思维:AB测试背后的逻辑做过科研的朋友们可能都能理解实验思维。所谓实验思维,就是一种帮助我们准确归因的思路。没有实验思维,你很难看到真实原因,你做的很多策略,最终都会徒劳无功。
具体来说,根据实验思维,要更好的进行归因实验,我们需要满足以下这几个条件:
对照:有其他对照组作为对比,就能真正看出来效果。而且不同组间的效果差异要足够明显,才能验证我们的判断
随机:为了排除实验条件以外的干扰因素,我们需要确保两个组的用户是随机选取的,这是为了排除用户差异对实验结果的影响
大样本:这里的样本量是指数据量,包括用户、行为和时间跨度,样本量越大,越容易排除个体差异的影响,也更容易验证统计上的显著性
谨慎推广应用:
在我们应用这些结论的时候,要特别小心,如果条件变动太大,这些策略就可能完全无效。比如你在今日头条上验证的判断,在趣头条上做效果可能会完全不同,因为两边的用户、环境、产品特点完全不同,直接迁移借鉴很难达成效果。测试实践在企业里,一般做AB测试有几块工作要做。分别是流量分配、实验设计和数据统计。
流量分配:
通常来说,产品快速迭代时,会有很多AB测试需要同时做,而产品的流量又是有限的,因此我们需要进行充分的流量切分。分流的逻辑如下图所示,这里有三个概念需要为大家澄清,分别是域、层、桶。
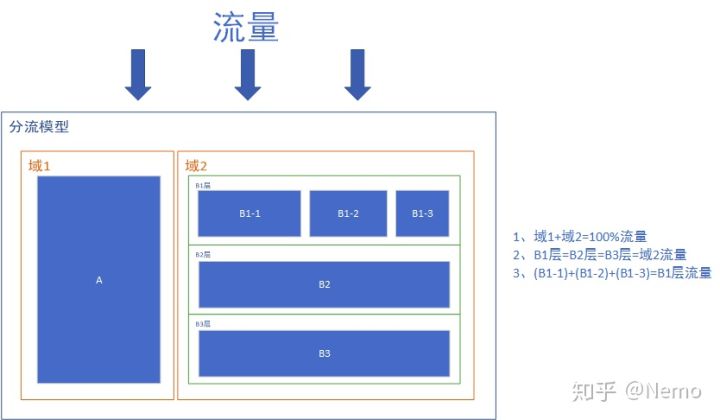
域:域是指整体流量的分区,域之间是互斥的。比如按照用户ID尾号奇偶性,将整体流量分为了1、2两个域,这个时候域1+域2=100%的流量,不同域之间的流量不会重叠。划分域的目的,是为了进行完全纯净的分区,更好的进行互不干扰的实验测试。
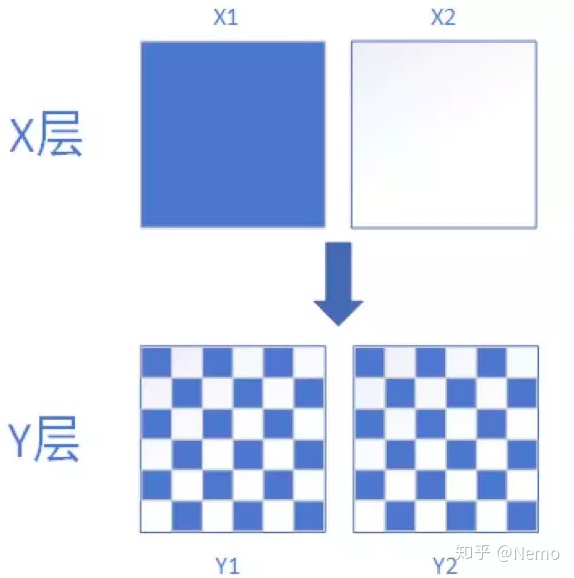
层:层是指某个域内全部流量的一个观测角度。比如对同一个域内流量,你可以按照用户ID尾号进行细分,也可以按照用户ID首号码进行细分。不同的细分方法,对应的也就是不同的层。不难理解,层与层之间的关系是正交的,即彼此互不影响,相互独立。可以同时进行实验而不互相干扰。如下图所示,每个层中的实验对其他层的影响都是正交的,参与层A中实验X的用户,均匀的分散在层B中,使层B中的实验也可以独立进行分析,并得到准确的分析结果。
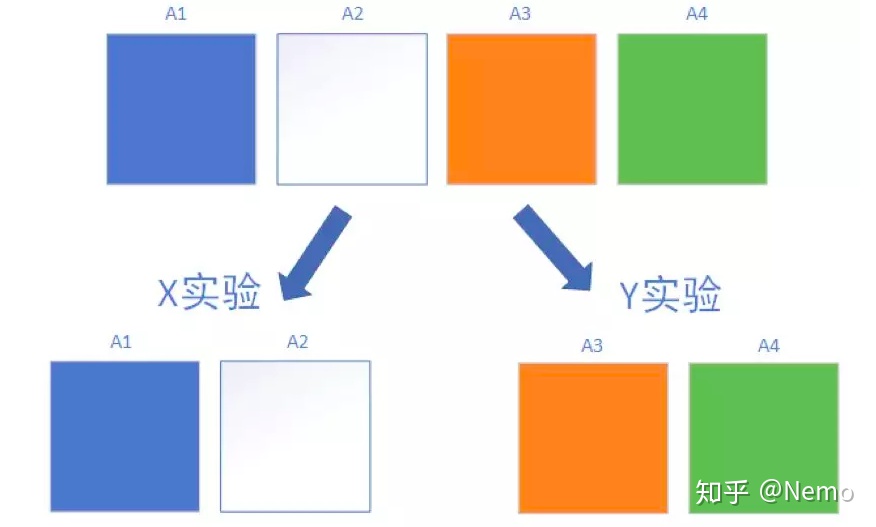
桶:在每个层中,我们使用独立的Hash函数对用户进行取模,将用户均匀的分配至N个实验桶中。桶与桶之间是互斥的。如下图所示,在A层中有A1/A2/A3/A4这4个桶,他们彼此互斥,互不重叠,彼此加和后等于层内的全部流量。我们可以用A1/A2进行X实验,同时用A3/A4进行Y实验
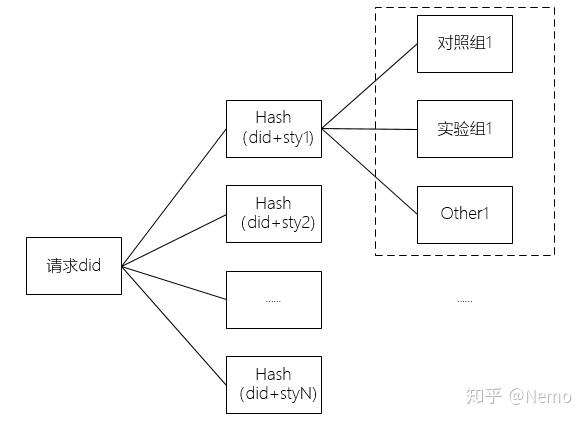
理解了以上规则,我们就可以根据实际业务需要,灵活的增加域、层、桶,满足实际工作中的测试流量需要。
在具体实践过程中,我们根据did+策略id进行hash分桶,来分对照组和实验组流量
实验设计:
1.单因素实验设计
所谓单因素实验设计,是指实验中只有一个影响因素变量,其他的内容都保持不变的实验方法。举个例子,两个实验组,一组用广告图A,一组用广告图B,这两个组进行实验对比,最后发现A组比B组效果好,那么我们就可以认为这是A广告图的作用。
2.多因素实验设计
多因素实验设计,是指实验中有多个影响因素变量。比如你想同时测试广告图(AB)和广告弹出方式(AB)对转化率的影响,这里面有两个变量,对应的有4种组合条件:
广告A,弹出方式A
广告A,弹出方式B
广告B,弹出方式A
广告B,弹出方式B
多因素实验设计的好处在于,除了可以检测同一个变量、不同实验条件之间的差异之外,还能对变量之间的交互效果进行检验。用上个例子做说明,如果在单因素AB实验里,我们发现广告A比广告B的效果好,弹出方式A比弹出方式B的效果好,但是广告A+弹出方式A的组合情况却不是最好的,因为他们之间的组合,产生了化学作用。这种情况下,就必须使用多因素实验设计来做。
数据分析:
1.考虑空跑期差异:
一个不用统计的简单分析方法,是考虑空跑期差异。所谓空跑期,就是指什么策略也不做,纯看两个组本身的固有差异,作为判断的基础。而后用实验期的差异减去空跑期差异,就得到了实验的真实收益。具体来说分这么几个步骤:
看两个组在空跑期的数据差异(百分比),判断组间差异基础
看两个组在实验期的数据差异(百分比),判断实验差异
用实验期的差异减去空跑期的差异,得到实验真实收益
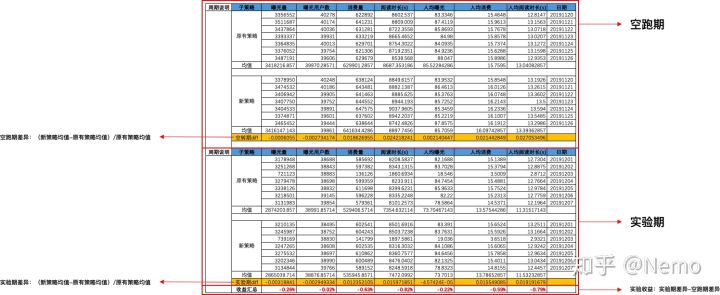
2.统计检验:
不考虑空跑期差异,而是直接看实验期里两个组的明细数据,输入到统计软件中进行统计分析,看是否显著(P
常用的统计分析有两种:
独立样本T检验
方差分析
举个例子:
假设我们进行A/B-test一周,参考版本(通常默认是原始版本,简记为A)和实验版本(添加了特定改进的版本,简记为B),分别得到了1000个线索,A的线索-车辆成交转化率为7%,B的线索-车辆成交转化率为8%。如表1所示:
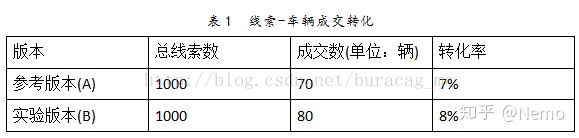
在这儿,我们是肯定B比A版本所带来的转化率高呢,还是说这仅仅是由于一些随机的因素导致的这样的区别呢?我们严格按照A/B-test显著性检验过程进行如下计算。
1).选取测量指标:
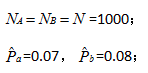
2).构建原假设和备择假设:

3).构建检验统计量:
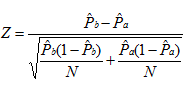
我们可以计算得到Z=0.849105726,
4).显著性检验结论:
如果取显著性水平=0.5,则=1.644854,所以不能拒绝原假设,即认为B版本不一定比A版本所带来的线索-车辆成交转化率高。
如果我们将A/B-test的时间拉长,如两周时长的A/B-test分别得到5000条线索量;或者说同样做一周时间的A/B-test,但是测试的比例更大,分别得到5000条线 索量。即 N=5000,且线索-车辆成交转化率保持不变。计算得出Z=1.89865812,在同样显著性水 平下,可以拒绝原假设,得出B比A版本所带来的线索-车辆成交转化率高的结论。
上述结论是符合我们的主观感受的!在小样本量时,新版所带来的线索-车辆成交转化率高于旧版本所带来的线索-车辆成交转化率,其原因也有可能是受到随机波动等因素影响,故不能肯定地说明新版要比旧版所带来的线索-车辆成交转化率高;但在大样本量时,或者说长期来看,新版本所带来的线索-车辆成交转化率都稳定地高于旧版本所带来的线索-车辆成交转化率,我们有理由相信,确实新版本所带来的线索-车辆成交转化率高于旧版本所带来的线索-车辆成交转化率。注意事项1.实验组控制组数量相等
最好保持实验组和控制组具有相同的用户比例,也就是如果实验组有5%的用户,那么控制也要选5%的用户做对照。背后的原因是对于未登陆用户,我们依靠浏览器 cookie 或者设备 id 来标识,一旦用户使用多个浏览器,多个电脑,跨设备,就会具有多个标识,很可能被同时分配到了控制组和实验组。我们认为这些标识都相互独立,其实都指向一个用户。如果这群用户具有和其他单设备单浏览器用户不同的特性(比如特别活跃),那么就会引入偏差,扭曲结果。处理的方法就是给予控制和实验组相同的比例,让这群同时进入实验和控制组的用户可以被等比例的删除。
2.不要反复统计
AB 测试上线后,是不能去反复查看 p 是否已经小于0.05,达到统计显著了。且不说上面提到的产品周期性和延迟性因素,p 本身就是一个随机变量,每观测一次实际上就是对其进行一次抽样,也就增大了统计显著的概率,同时增加了 FP 的概率。那什么时候能观察结果呢?就是等到事先设定好的运行时间结束,然后看一次,决定是否统计显著。
3.上线后及时观察一下
实验上线后就要开始紧密观察,但这时观察不是看有没有统计显著(请暂时忽略 p 值),看的是实验和控制组的指标读数是否符合预期,有没有出现完全无法解释的情况。如果感觉奇怪,不要犹豫,排查下有否程序漏洞,如果对产品出现明显负面影响,考虑立即回滚。
至于 p 值,还是要等到预定的测试时间完成后,才能采样一次用来做判断。
4.评估长期影响
是有可能的。测试完成,实验组的指标提升统计显著,可真全面推广上线了,过段时间发觉成功指标或者其他监测指标可能降低到原有水平甚至更低了。这对一些长期 KPI,比如 LTV,留存,年营收等要特别留意。应对的方法是保留一个全局对照组(比如5%的流量),全局对照组相对稳定,一个季度,甚至一年都不进入任何测试,长期处于“控制组”状态,用来对比各个测试全面上线后的长远影响,出现情况时就需要部分或者全面回滚相应测试。当然,这个全局对照组的比例不能太大,否则机会成本太高。
5.排除异常值
作弊用户和BUG数据,可能会让指标变得非常奇怪
6.服务端做控制更好
客户端要发版,服务端可以更好的控制内容
7.不要反复用同一组用户实验
根据用户尾号分桶做实验,很容易出问题。也许刚开始因为其随机性,桶间用户行为差异很小。但第一个实验过后,桶间就开始有了行为差异——这也是 ABTest 的目标。N 个实验过后,桶间行为的差异可能就变得非常大了。比如你总是在 001 桶的用户上实验幅度较大的促销活动,那么 001 桶的用户留存就会显著高于其它桶。那实验人员为了让实验效果更好看,可能会偷偷地继续选择 001 桶进行实验。

