95后哈佛小哥撰写从零开始的机器学习入门必备,书籍资源已开放
机器学习怎么入门最简单?今年刚刚从哈佛大学统计专业毕业的 Danny Friedman 写了一本「转专业学生专用教材」,无基础也可轻松入门,资源现已全部开放。
说起机器学习入门书,大概有成百上千种选择。这些书籍大多是由具备丰富研究经验的学者撰写的,涵盖各种主题。
俗话说「开卷有益」,但对于转专业的初学者来说,这本新书或许更适合入门:
近日,一位毕业于哈佛大学的小哥根据自己的机器学习入门经历,撰写了一本《从零开始的机器学习》。

书籍地址:https://dafriedman97.github.io/mlbook/content/introduction.html
这本书涵盖了机器学习领域最常见的方法,就像是一位机器学习工程师的工具箱,适用于入门级学习者。撰写目的是为读者提供独立构建一些基本的机器学习算法的实践指导,如果用工具箱类比的话,就是教会读者具体使用一把螺丝刀、一盒卷尺。书中的每一章都对应一种机器学习方法。

作者 Danny Friedman 介绍说,学习一种方法的最佳方式就是从零开始(无论是从理论上还是代码上),因此本书的宗旨也是提供这些推导过程。每章分为三个部分:首先是从「概念」上进行介绍,并且从数学层面演示推导过程;然后是「构造」部分,如何使用 Python 从零开始演示这些方法;最后的「实现」部分介绍了如何使用 Python 包应用这些方法,比如 scikit-learn、 statsmodels 和 tensorflow。
这本书面向的是机器学习领域的新人,或者是希望深入了解算法的学习者。阅读书中的推论可能有助于以前不熟悉算法的读者充分理解方法背后的原理,也能帮助有建模经验的读者了解不同算法如何建模,并观察每种算法的优缺点。
章节介绍
在阅读这本书的「概念」部分之前,读者应该熟悉微积分的知识,有的部分可能会用到概率的知识(最大似然和贝叶斯定律)以及基础的线性代数(矩阵运算和点积)。这部分还引用了一些常见的机器学习方法(附录中有介绍),但「概念」部分不需要编程知识。
「构造」和「代码」部分会用到一些 Python 的知识。「构造」部分需要了解对应内容部分,并熟悉 Python 的创建函数和类。这些「代码」部分均不需要。
全书目录如下:
1. 普通线性回归(Ordinary Linear Regression)
最小化损失(The Loss-Minimization Perspective)
最大似然(The Likelihood-Maximization Perspective)
2. 线性回归扩展(Linear Regression Extensions)
正则回归(Regularized Regression)
贝叶斯回归(Bayesian Regression)
广义线性模型(Generalized Linear Models)
3. 判别分类(Discriminative Classification)
逻辑回归(Logistic Regression)
感知器算法(The Perceptron Algorithm)
Fisher 线性判别(Fisher’s Linear Discriminant)
4. 生成分类(Generative Classification)
线性和二次判别分析、朴素贝叶斯 (Linear and Quadratic Discriminant Analysis、Naive Bayes)
5. 决策树(Decision Trees)
回归树(Regression Trees)
分类树(Classification Trees)
6. 基于树的集成方法(Tree Ensemble Methods)
Bagging
随机森林(Random Forests)
Boosting
7. 神经网络(Neural Networks)
线性回归是一种相对简单的方法,用途极为广泛,所以也是必学算法之一。
第一章介绍了普通线性回归,第二章主要介绍了线性回归的扩展。可以通过多种方式扩展线性回归,以适应各种建模需求。正则回归惩罚了回归系数的大小,以避免过度拟合。这对于使用大量预测变量的模型尤其有效,贝叶斯回归对回归系数进行先验分布,以便将关于这些参数的现有观念与从新数据中获得的信息相协调。最后,广义线性模型(GLM)通过更改假定的误差结构并允许期望值来扩展常规的线性回归。目标变量是预测变量的非线性函数。
分类器是一种有监督的学习算法。它试图识别观察值对两个或多个组之一的成员资格。换句话说,分类中的目标变量表示有限集而不是连续数的类。例如,检测垃圾邮件或识别手写数字。
第三章和第四章分别介绍了判别分类和生成分类。判别分类根据观察变量的输入变量直接对其进行建模。生成分类将输入变量视为观察类的函数。它首先对观察值属于给定类的先验概率建模。然后计算观察观察值以其类为条件的输入变量的概率。最后使用贝叶斯定律求解属于给定类的后验概率。逻辑回归不是唯一的区分性分类器,书中还介绍了另外两种:感知器算法和 Fisher 线性判别法。
第五章演示了如何构建决策树。第一部分涵盖了回归任务,其中目标变量是定量的;第二部分涵盖了分类任务,其中目标变量是分类的。
决策树是用于回归和分类的可解释机器学习方法。树根据所选预测变量的值迭代地拆分训练数据的样本。每次拆分的目的是创建两个子样本(即「孩子」)。其目标变量的 purity 高于其「父亲」。对于分类任务,purity 意味着第一个孩子应该观察一个类别,第二个孩子主要观察另一个类别。对于回归任务,purity 意味着第一个孩子的目标变量值应该较高,而第二个孩子的目标变量值应该较低。
以下是使用 penguins 数据集的分类决策树的示例:
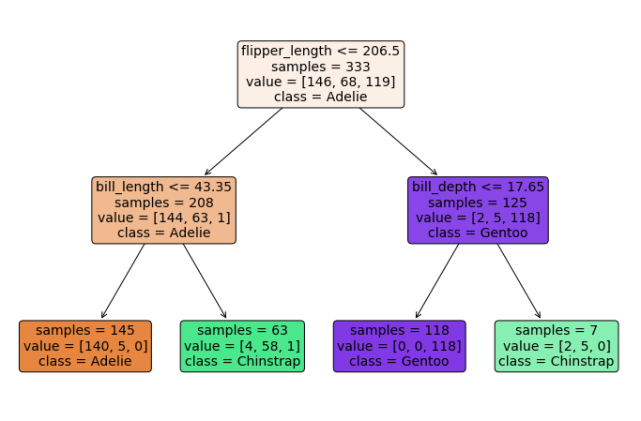
由于其高方差,决策树通常无法达到与其他预测算法可比的精确度。在第五章中介绍了几种最小化单个决策树的方差的方法,例如剪枝或调整大小。第六章将介绍另一种方法:集成方法。集成方法结合了多个简单模型的输出,以创建具有较低方差的最终模型。书中在基于树的学习器的背景下介绍集成方法,但集成方法也可以用于多种学习算法。在这本书中,作者讨论了三种基于树的集成方法:bagging、随机森林和 boosting。
第七章介绍了神经网络,一种功能强大且用途广泛的模型,已成为机器学习中的一大热门话题。尽管神经网络的性能通常胜过其他模型,但神经网络也不像想象中那么复杂。相反,通过优化高度参数化和非线性的结构,神经网络具有足够的灵活性对其他模型难以检测到的细微关系进行建模。
这一章按照如下结构展开:
1. 模型结构
概述
层与层之间的交互
激活函数
2. 优化
反向传播
计算梯度
将结果与链式法则结合
3. 结合观察值
一种新的表征
梯度
其他资源推荐
此外,作者还推荐了三本经典的机器学习理论入门书籍,也都能在网络上获取免费资源:
1、《统计学习导论:基于 R 应用》

资源地址:http://faculty.marshall.usc.edu/gareth-james/ISL/
2、《统计学习的要素:数据挖掘、推理和预测》

资源地址:https://web.stanford.edu/~hastie/ElemStatLearn/
3、《模式识别与机器学习》

资源地址:https://www.microsoft.com/en-us/research/publication/pattern-recognition-machine-learning/

